
目次
Amazon Athena は Google BigQuery と MS PolyBase を足して2で割ったようなサービス
昨年末、Amazon Web Services(以下、AWS)が主催したAWS re:Invent 2016から新しいAWSのクラウドサービスが多く発表されました。その中の主要サービスの1つに「Amazon Athena」があり、発表直後から様々なメディア、ブログなどで取り上げられた。そして、弊社としてもAmazon Athenaに可能性を感じ、技術検証を行ってきました。今回は技術検証したAmazon Athenaについて、類似クラウドサービスとの比較しながら分析サービスとしての位置付けについてご説明したいと思います。
Amazon Athena とは?
Amazon Athena(以下、Athena)は、数あるAWSサービスの中のデータ分析サービスの1つとして発表されました。現時点(2017.02.06)では米国リージョン(バージニア北部、オレゴン)のみのリリースですが、日本からサービスを利用することができます。
Athenaは、大量、かつ様々な形式のデータファイルを高速、簡単、そして安価に分析することにデータ分析が可能です。データ形式はCSV、TSV(CSVのタブ区切り)、JSONなど扱え、1テラバイト以上のデータ量にも耐えることが可能です。そして、基本的なSQL命令でデータ操作が行えるため、まるでデータベースを操作している感覚でデータ分析が行えます。
課金体系とテーブル定義は Google BigQuery に近い
Googleなどの検索サイトで「Amazon Athena」を検索すると、上位でGoogle Cloud PlatformのBigQueryがヒットするぐらい、AthenaとBigQueryとではSQL命令でデータ分析ができるなどの共通点が多いです。特にその中で課金体系とテーブル定義について、BigQueryと非常に似ているため、この2つについて少し深掘りしたいと思います。
【参考】Google BigQueryは「速い・安い・シンプル」の3拍子揃ったビッグデータ処理サービス ~3大クラウドサービス比較~
課金体系
クラウドサービスは使用したサービス量による従量課金が行われ、使用時間やデータ使用量/記憶容量などによって使用料金が決まります。下記は代表的なビッグデータ用の分析サービスごとの10テラバイトの月間使用料金になります。(AWSは米国オレゴンリージョンの価格)
今までAWSのデータ分析サービスはRedshiftのように起動時間によって課金される「使用時間課金」がメインでした。しかし、今回、Athenaを発表したことにより、「使用時間」ではなく「データ使用量」をベースとした課金体系が登場しました。これによってAthenaサービスを使用していない時間は殆ど課金が発生しなくなります。記憶しているデータ記憶容量によって課金は発生しますが、Redshiftの月額料金に比べて大変安価にデータ分析が可能です。反面、試行錯誤で大量データを何度もデータ分析命令を実行する場合は使用料金が膨れ上がる場合があります。
テーブル定義
通常のデータベースのテーブルでは、各データ項目(カラム)をデータ型と桁数(バイト数)などで定義する必要があります。例えばRedshiftの文字列が入るデータ項目の場合、データ型はchar、またはvarcharになり、対象項目の最大文字数が登録できる桁数を確保する必要がありました。もし、この桁数より文字列をテーブル登録しようとした場合、データベースエラーが発生していました。
しかし、Athenaのデータ項目の定義方法はデータベースと異なり、桁数のないデータ型だけでの定義になります。下記はAthenaとBigQueryのデータ型の比較ですが、赤字で示したように共通する部分が多くあります。(AthenaのarrayとBigQueryのrecodeを同じものとしています)
- 【Athena】string、tinyint、smallint、int、bigint、boolean、float、double、array、map、timestamp
- 【BigQuery】string、bytes、integer、boolean、float、recode、timestamp
このようにデータ型の定義をシンプルにすることでデーブル作成を簡単にできます。反面、データベースのNUMBER型のように整数桁と小数点以下の桁数が明確に定義しているデータ型がなく、float型などで代用する事になるため、浮動小数点型による丸め誤差が発生する可能性があるため、小数点以下の厳密な計算処理などには不向きな部分があります。
データと処理エンジンの関係は Microsoft PolyBase に近い
通常、クラウドサービスのデータベースサービスは、データとデータベースエンジンが密接な関係になり、RedshiftやBigQueryなどにデータを登録する場合はデータインポート作業が必須となります。しかし、Athenaは、データと処理エンジンが完全に独立し、分析対象データファイルはAmazon S3というクラウドストレージに登録し、AthenaはそのS3上のデータファイルを参照するような形式になります。
このデータと処理エンジンの関係は、Microsoft AzureクラウドのAzure Blob StorageとPolyBaseなどの外部参照テーブルに似ています。PolyBaseはAzure SQL Data Warehouse内に組み込まれており、Blob Storage上のデータファイルを参照する外部参照テーブルを作成することで、SQL命令を使用して参照先のAzure Blob Storage内のデータファイルを分析することができます。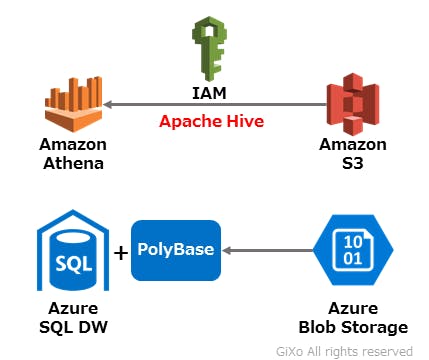
データとエンジンが完全に独立していることで、クラウドストレージにため込んだデータファイルを後からデータ参照して、瞬時にデータ分析作業が行えます。日々、増えていくログデータなどは、とりあえずS3に保存し、障害発生時にAthena経由でSQL命令を使って障害原因の調査などが行えます。また、S3にデータファイルを登録するだけなら、1テラバイト当たり月$2.3程度のデータ記憶容量と微々たるデータ転送料金しか掛からないため、常にデータ蓄積する必要があるが、データ参照するのは月数回程度の運用ならコストを削減できます。
【参考】PolyBaseを使ったAzure SQL DWへの高速インポート ~図解で分かりやすく説明~
Amazon Athena のココがイケてる
Athenaは新しい分析サービスです。しかし、決して新しい技術習得は行う必要がなく、大概の事は普通のデータベースを使う感覚で操作できます。
Athenaはビッグデータ分析で使用されるApache Hiveを使いSQL命令でテーブル作成とデータ分析を行います。Hiveのテーブル作成のSQL命令は若干の癖はありますが、AWS管理コンソールを使うことでWebブラウザから基本的なテーブル作成のSQL命令文を生成できるため専門的な知識は必要ありません。そして、AWSでお馴染みのS3クラウドストレージの保存場所の設定とIAMによるアクセス権限を行えば環境構築が完了します。そのため、AWSとSQL命令の基本的な知識があればAthenaを使用することができます。
また、SQL命令を実行する環境は、専用のAthena JDBCが配布されているため、OSを選ばず、SQL Workbench/JのようなSQL実行ツール、TalendのようなETLツール、Javaプログラミングなど様々な所でAthenaを操作することが可能です。
データフォーマットが固定されていれば初期分析として十分使える
Athenaの機能説明には「サーバーレス。ETL 不要。」とありますが、ETL処理のうち「Transform(変換)」処理だけはHiveの機能限界があるため、Athenaで解析できる形に整形が必要になる場合があります。しかし、テラバイトクラスのデータを分析するサービスとして、クイック、かつ安価に行えるAthenaサービスは非常にインパクトがあります。
しかし、Athenaの処理速度の改善にはHiveの専門的な知識は必要になるでしょうし、試行錯誤で何度も実行するのにはコスト面でのメリットは薄れます。そして、Athenaはデータ参照に重点を置いたサービスであるため、データ追加/変更/削除はSQL命令では行えません。そのため、データの初期分析はAthenaで、分析するスコープが絞れたらS3のデータファイルをRedshiftなどにインポートしてデータ分析の深掘りをするのが適切だと思います。
(2017.04/25 Update)
Athena のテーブルを Redshift から参照する「Amazon Redshift Spectrum」がリリースされました。弊社で検証した内容については「Amazon Redshift Spectrum を使ってみた ~Redshift Spectrum は Redshift のデータレイクの入り口になる~」をご参照ください。
連載記事一覧はコチラ:category / AWSを使い倒せ





