
ギックスの分析プロセス
ギックスのビックデータ分析体系の第一回では、「ぜひ企画部の皆様にビックデータ分析をしてみてほしい。テクノロジーが進歩してそういう環境が整ってきています」というお話をしました。
今回、第二回は、具体的にどのような順序で分析していけばよいかという分析プロセスについて説明していきます。ギックスのビックデータ分析体系の図では、以下の赤枠部分のお話です。
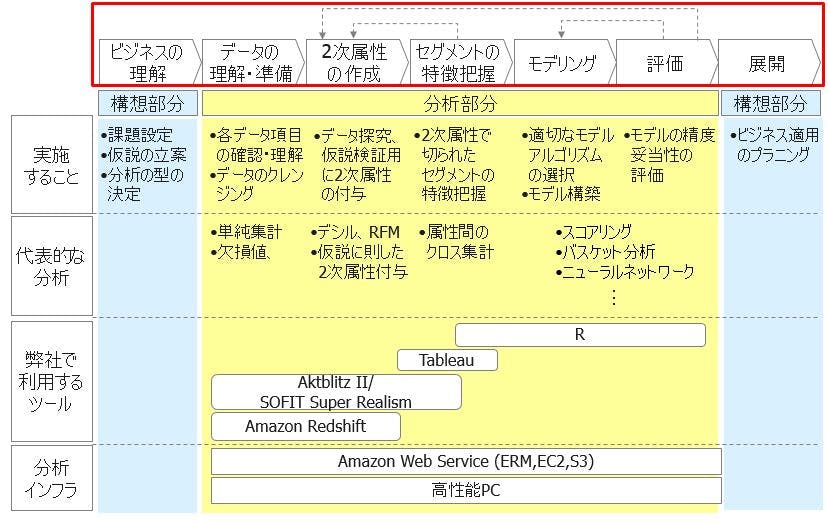
実はデータマイニングのための標準的プロセスとして、CRISP-DM(Cross-Industry Standard Process for Data Mining)というものが存在しています。SPSS(現在IBMが買収)、NCR、ダイムラークライスラー、OHRAなどがメンバーになったコンソーシアムで開発されたプロセスだけあり、汎用性の高いよくできたプロセスです。
ただ、我々が実務上で顧客データでのビックデータ分析を対象とした場合、CRISP-DMをベースに少し変更したほうがよいと考え、以下のようなギックス独自のプロセスに変更しています。
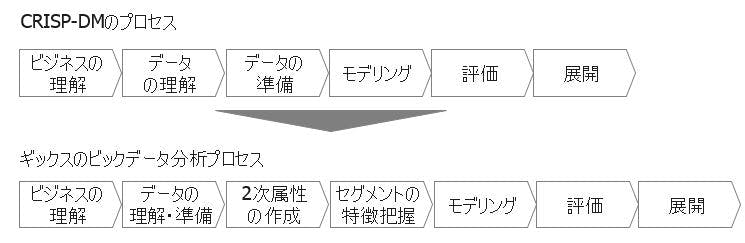
具体的には、「データの理解」と「データの準備」を一つのプロセスに統合し、「モデリング」との間に、「2次属性の作成」と「セグメントの特徴の把握」という項目を入れています。
「2次属性の作成」と「セグメントの特徴把握」の重要性
その理由をもう少し説明します。
まず「データの理解」と「データの準備」を統合したのは、最近はソフトウェアの進化でビックデータを扱ったとしてもそこの作業が簡単にできるようになったからです。わざわざプロセスを2つに分けなくても一気に作業してしまえるという判断です。
次に「2次属性の作成」と「セグメントの特徴把握」という項目を入れたのは、顧客データ分析ですと、モデリングする前に、この2つのプロセスの作業を繰り返し行うだけで、セグメントに切った顧客の特徴を把握でき、示唆出し、施策につなげていけることも多いからです。
昨今の統計ブーム、ビックデータブームの中、注目が集まるのは、このビックデータ分析プロセスのところでいうところの「モデリング」になります。「購買顧客のスコアを付けました」「協調フィルタリングでリコメンドエンジンを作りました」みたいな花形の話は、このモデリングの部分の話です。
モデリングはもちろん効果が高く、ギックスでもさまざまな統計モデルを作っていますが、実際の実務の場においては、ビックデータをお預かりした場合、モデリングに行く以前に、まずそのデータを仮説をもってさまざまな角度から見える化していくだけで今まで見えなかった顧客の特徴が見えます。決して難しい作業ではないですが、この当たり前のことを新しいテクノロジーを使って当たり前に検証、確認することが重要かつ効果的です。
その重要性を強調したいので、ギックスのビックデータ分析プロセスでは「2次属性データの作成」と「セグメントの特徴把握」というプロセスを切り出しています。
次回以降、具体的な作業内容を詳細に説明していきます。2次属性という聞きなれない概念の説明もそちらにて。
- PC上で数千万件データを手軽に扱える時代がやってきた
- CRISP-DMをマーケティング領域へ適用させる (今回)
- ビジネスへのインパクトを「常に」念頭に置こう
- 2次属性を理解しよう
- クロス集計で「セグメント間の違い」を見出せ
- もう一歩踏み込みたい方は「モデリング」を学ぼう
- 大規模投資の前のトライ&エラーが重要
- Quick Startのための分析ツールとは
- Quick Startのための分析インフラとは





