
データレイク(Data Lake)はファイル置き場
こんにちは、技術チームの岩谷です。先日とある方より「このごろデータレイクって言葉をよく聞くけど、”Data Lake→データの湖”ってどういう事?」という質問をいただきました。この場を借りてちょっと説明をさせてください。ちなみに「これがデータレイクだ!」という定義が完全に定まっていない言葉なので、その思想について述べさせていただきます。
まず、「データレイクはビッグデータを扱うためのストレージ(ファイル置き場)です。」これが今現在の一番シンプルな答えです。
その名前の由来についてですが、データウェアハウス(DWH)が「データの倉庫」、データマート(DM)は「データの市場」であるのに対して、データレイク(=データの湖)は、DWHやDMよりも、より「自然に近い(生の)データの置き場所」という意味を持っています。
すなわち
- 生データを最初に湖(データレイク)に入れて
- 次に倉庫(データウェアハウス)に移して
- 次に市場(データマート)に運び込む
というプロセスをイメージした命名であると考えられます。
普通のストレージとはどう違うのか?
データレイクというストレージが世の中に現れた背景には「今のストレージでは満足できない、もっと便利なものがほしい。」という願いがあるはずです。それはなんなのでしょうか?今現在の私の解釈は以下の二つです。
1.非定型データからのデータ取り出し
例えば、ストレージ上に分析データとして「購買データログが2個」あったとします。ログ①はCSVファイル、ログ②はJSONファイルであったとします。
ストレージの立場から見た場合、この状態は「自身が格納しているデータの形式が複数ある、または決まっていない」という状態です。このような状態を「ストレージに格納されているデータは”非定型データ“※1である。」と呼びます。
これら「非定型データ」をデータウェアハウス(DWH)に投入したい場合、CSVファイル用のデータ投入プログラムでログ①のデータをDWHに入れて、JSONファイル用のデータ投入プログラムでログ②のデータをDWHに入れなければなりません。「ファイルからデータを取り出す方法」を「ファイルの形式ごと」に分けなければいけないのです。
「これが煩雑だ、満足できない。なんとかしたい。」という願いがデータレイクの目指すところの一つです。すなわち「ファイル形式を横断してデータを取得できる共通的なデータアクセス言語※2」を用いていろいろな形式のデータファイルから目的のデータを取り出せるようにする事、これがデータレイクの機能の一つです。これによってデータ投入プログラムを削減できますし、新しいフォーマット(例えばXML)のデータがストレージに格納されたとしても新しくデータ投入プログラムを作成する必要がありません※3。
※1…この「非定型データ」を同様の意味で「非構造化データ」「多構造化データ」と呼ぶ場合もあります。
※2…おそらくは「SQLっぽい/XPathっぽい/JSONPathっぽい」モノになるであろうと思われます。この言語がなんになるのかはデータレイクを提供するサービスによって別々になるでしょう。
※3…「それってETLツールじゃないの?」と思われるかもしれません。それは一部その通りです。データレイクは「ETLツールの機能を包含したストレージ」とも表現できます。でも決定的に異なる点が一つだけあります。それは「ETLツールがデータをストレージに”投入”するときに非定型データの形式の違いを吸収する」のに対して「データレイクはデータを”取り出す”ときに非定型データの形式の違いを吸収する」という違いです。取り出すときに違いを吸収してくれたほうがユーザのわがままな利用シーンに対応しやすいので、この点はデータレイクのメリットの一つです。
2.分散処理に対する最適化(Hadoopへの対応)
ストレージにはビッグデータが格納されるために、ストレージのデータの処理には時間がかかります。これを少しでも短縮するために分散処理の仕組みを用いて処理を高速化している方々は多いと思います。代表的な例が「Hadoopを導入してビッグデータを処理している」という取り組みです。
Hadoopでのビックデータ処理は、経験の積み上げによって以下のようにパターン化されています。
データレイクはこの状態を、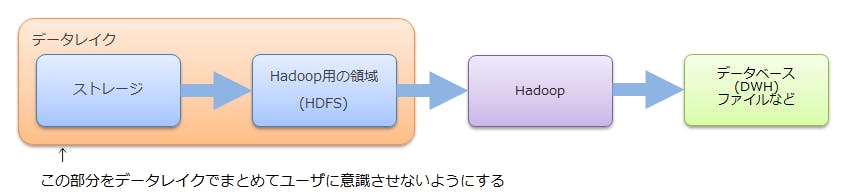
のように、ストレージとHadoop用の領域(HDFS)を「データレイクという一つのストレージ」として見せることで、ユーザがHadoopを扱う上での作業負担を軽減する事を目的としています。また、データレイクをサービスとして提供するベンダは、多くの場合「Hadoopのそのもの」もサービスとして提供することでしょう。この「データレイクによるストレージとHadoopの密接な連携」と「Hadoopのサービス提供」という二つの要素の両立が「Hadoop処理の一気通貫の処理プロセス」をもたらす事で、より効率的で強力なビッグデータ処理を実現しようとしているのです。
今回はデータレイクについて説明させていただきました。データレイクはまだ発展途上の技術・サービスですが、誕生した背景には世の中のたしかなニーズを感じます。これからいろいろな機能を取り込んでいきながら熟成していくのでしょう。私も楽しみです。
【関連記事】






