
文字コード?文字化け?このモヤモヤ、気になっていませんか?
こんにちは、技術チームの岩谷です。前回のデータフォーマットに関する連載で私は文字コードについて少しだけふれました。あれから何人かの方から「文字コードについて”ああ~あらためて言われるとたしかにそうだよね~”って思ったよ」とコメントいただきました。たしかにExcelでCSVファイルを開いて文字が化けていた時、苦労して作成したプログラムの出力ファイルが文字化けだった時などの精神的ダメージは大きいですよね?そんなわけで今回の連載では簡単な文字コードの説明と文字コードの違いから起こる文字化けの種類をかいつまんで書かせてください。文字コードのモヤっとをスッキリにできたらと思っています。
Note:文字化けの原因は文字コードに起因するものだけではないのでご注意ください。実際、昔のE-Mailにおける文字化けの多くはデータの欠落が大きな要因でした。
文字コードとは?をさらっと
文字コードとはコンピュータ上で文字を扱うにあたっての表現を定めた世界的な規約です。文字コードの種類(ルール)にはいくつかの種類があります。今の日本で使用されている代表的な文字コードにはShift-JISやUTF-8があります。
例えば私の名前(岩谷)の「岩」をコンピュータ上であらわすと、Shift-JISでは「1000101011100010」というコンピュータ上でのデータ表現になります。対してUTF-8では「111001011011001010101001」というデータ表現になります。まったく違うデータ表現結果になりましたね。
逆に言うと、コンピュータではデータ0と1でデータを格納しているに過ぎないので、プログラムが自身はそれが何の文字コードで表現されているかを知ることはできません。もっと言うとそれが文字データであるかすらもわからないのです。文字データをプログラムが文字を処理する為にはプログラムに対して「この0と1の羅列は文字データとして処理してね。文字コードはXXXだよ。じゃあ、あとはがんばって。」というように文字コードを事前に教えてあげなければいけないのです。(一部例外はありますが割愛します)
まずはこの表を見てください。
これは一つの文章を例文として、それをいろいろな文字コードで表現したものです。

この例文を以下の文字コードで表現してみます。
- Shift-JIS
- GB2312
- UTF-8
- UTF-16
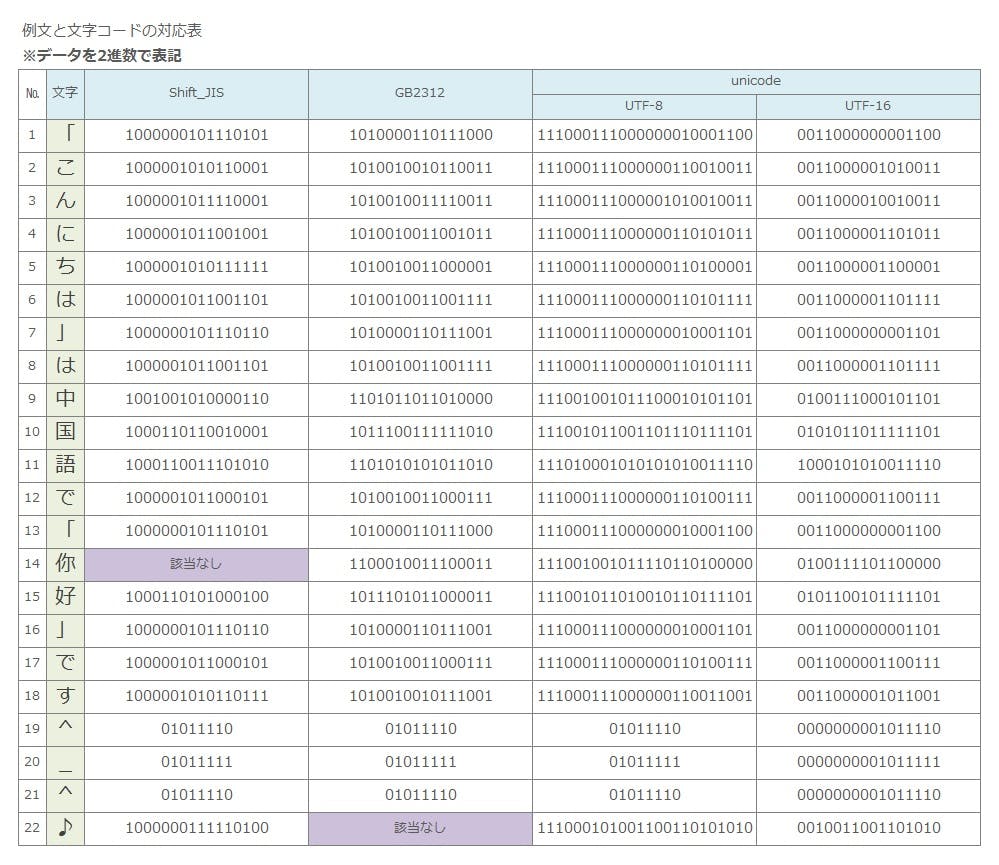
コンピュータは内部でデータを0と1で表現しますが(2進数)、これでは非常に見づらいのでデータを16進数に表記しなおして見ましょう。以下の表になります。

冒頭でも述べましたが、同じ文字でも文字コードによってコンピュータ上での状態(0と1)が大きく異なることがお分かりいただけると思います。と同時に「同じ0と1の表現をしてる所もある」事が興味深いと思います。
ここで、本連載で取り上げる文字コードの簡単な説明をします。
1.Shift-JIS
コンピュータ上で日本語を表現するために利用されている文字コードです。1982年に生まれました。誕生経緯には諸説あるものの、日本企業・団体の大きな関わりをもって策定された規格であることにまちがいはないでしょう。現在はJIS(日本工業規格)で規定されています。ということは日本の国家標準の一部を構成する規格であり、このことから「Shift-JISは日本国の為に存在する文字コードである」と言えます。
2.GB2312
コンピュータ上で中国語を表現するために利用されている文字コードです。1981年に中国の国家標準総局から発布される形で中国の国家標準の一部を構成しています。このことから「GB2312は中華人民共和国の為に存在する文字コードである」と言えます。
3.UTF-8
「地球上で使われている文字を全て収録したい」という目的の元に作られた文字コードです。今日我々は多くのコンピュータ資産とふれあいながら生活していますがそのコンピュータがやりとりをする為の多くのルールがRFC(Request for Comments)という公開形式にもとづいた仕様に則っています。UTF-8はRFC 3629という管理番号で公開されています。公開は2003年です。現在(2015年)、インターネット上でやり取りされる文字データの文字コードとして最も利用されているであろう文字コードです。UTF-8の誕生にはグローバル企業が数多く参加しているユニコードコンソーシアムが大きく関係しています。「UTF-8はグローバルな活動の為に存在する文字コードである」と言えるでしょう。
4.UTF-16
UTF-8と同じく「地球上で使われている文字を全て収録したい」という目的の元に作られた文字コードです。UTF-8と同様RFCに則って公開されており、管理番号はRFC 2781です。公開は2000年です。誕生にもユニコードコンソーシアムが大きく関係しており「UTF-16もグローバルな活動の為に存在する文字コードである」と言えるでしょう。「…?じゃあUTF-8とどう違うんだ?!」とツッコミを入れたくなられると思います。その話題は次回以降の連載で述べさせてください。実はこのあたりの説明を後回しにしたいために、今回のUTF-8,UTF-16に関する説明をすごくあいまいな記述にとどめさせていただいています。
今回はここまでです。冒頭に「モヤっとをスッキリに」と言っておきながら余計にモヤっとさせてしまってすみません。次回以降この表のいろいろな部分にフォーカスをあてていくことによって文字コードのモヤっとを紐解いていきたいと思います。本連載もどうぞよろしくおねがいいたします。
追伸:
話のオチを一つ先に書いてしまうと、この記事が文字化けせずに表示されているのは、このブログのhtml文字コードがUTF-8であるからなのです。(^_^)v
【連載記事:いまさら訊けないビッグデータ分析】
- 文字コードや文字化けを理解しよう(その1) (本編)
- 文字コードや文字化けを理解しよう(その2)
- 「データマート」と「キューブ」の違いとは?
- カラムナー、キューブ、インメモリ…ビックデータ分析におけるデータベースのまとめ






