
TableauとRを連携させる
前回は、Tableauが提供しているパッケージワークブックを使い、TalbeauとRを連携させると何ができ、また具体的にどのようにTalbeuとRが連携されていくのかを見てきました。今回は、手持ちのデータをTableauとRの連携環境でどのように動かすのかを確認します。また、TableauでRに受け渡す変数を動的に変更する方法についても紹介していきます。
手持ちのデータをTableuとRの連携環境で動かす
今回は、新たにパッケージワークブックを作るところから始めます。再度、繰り返しますが、Tableauは、ver.8.1、又はver.8.2である必要があります。
データは、irisを使います。irisは、R環境にあるものをcsvファイルに吐き出しておく必要があります。以下のRコマンドで、csvファイルを作成しましょう。
>write.csv(iris,”IrisData.csv”)
上記コマンドを実行することで、作業フォルダにirisのcsvファイルが作られます。作業フォルダを確認する場合は、{getwd}関数を呼び出します。
ところで、TableauとRの連携が出来ているのだから、R形式で保持されているのirisデータを直接参照すれば良いのでは?と感じた方がいるかもしれません。しかし、それは出来ないのです!TableauとRの連携で可能なことは、Tableauから[SCRIPT_*]関数を利用して、Rの関数を呼び出すことです。従って、Rに用意されているサンプルデータを利用する際は、あらかじめcsvファイル等に吐き出しておく必要があります。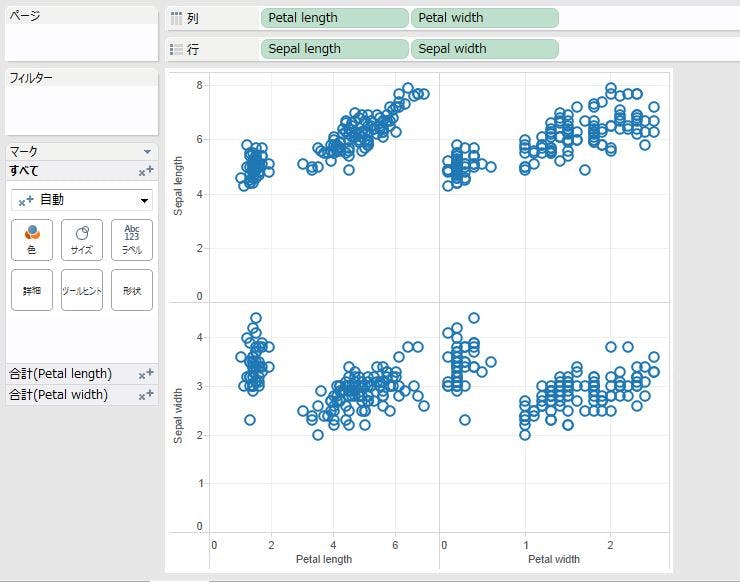
データの準備は整いました。早速、TableauからIrisData.csvに接続しましょう。接続したら、最初に、行と列にPetal(花びら)とSepal(がく片)の長さと幅を配置して、グラフの土台を作成します。
一つ注意が必要です。データ項目をシェルフにドラッグ&ドロップする前に、少し設定を変えておきます。メニューの分析>メジャーの集計をクリックし、メジャーの集計が自動的に実行されないようにしておく必要があります。Tableauでは、初期状態では、メジャー項目をシェルフに移動することで、自動的に集計処理が実行されるようになっているからです。
シェルフへのドラッグ&ドロップは、以下のようにします。
列: Petal length、Petal width
行: Sepal length、Sepal Width
上記のように配置することで、グラフの土台が出来上がったと思います。
次に計算フィールドを作成しましょう。計算フィールドの中で、[SCRIPT_INT]関数を利用し、Rの{kmeans}関数を呼び出すのでした。メジャー欄で右クリックし、「計算フィールドの作成」をクリックします。「計算フィールド」ダイアログが表示されますので、以下のように各項目を指定します。
名前: Clusters
式: SCRIPT_INT(‘set.seed(42);result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4), 3);result$cluster;’,
SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]))
入力後、式の欄下に「計算は有効です。」と表示されれば、この計算式の定義は問題ありません。
入力した式をもう少し細かく見ます。
・[SCRIPT_*]関数では、Rのコードを文字列として受け取ります。従って、Rのコードは、'(シングルクォーテーション)、又は、”(ダブルクォーテーション)で括る必要があります。
・TableauからRへデータを受け渡す場合は、.argN(N=1,2,3,,,)と指定します。argの前に.(ドット)が必要です。実際のデータは、Rコードの後に、.argNに対応付けるよう指定していきます。
・データを指定する際は、集計か定数である必要があります。従って、各データの項目を[SUM]関数を利用して指定しています。
# 補足
Rコードを見て、set.seed(42);は何だろう?と思った方がいるかもしれません。実は、この関数の呼び出しは、クラスタリングそのものには必須ではありません。ただ、k-meansクラスタリングは、アルゴリズムの特性上、初期値に依存したものであるため、ここでは、同じ結果を再現できるように初期値となる乱数(の種)を指定しています。
ここまで来れば、あと一息です。
次に、作成した計算フィールドを「不連続」にしておきます。この計算結果は、クラスタリング結果を返しており、クラスタ数を3と指定していますので、結果は、1or2or3のいずれかです。メジャー欄の[Clusters]のメニューから「不連続に変換」をクリックします。
最後に、[Clusters]項目をマーク欄の「色」にドラッグ&ドロップします。ここまで問題なく作業を進めていれば、以下のような結果になった筈です。
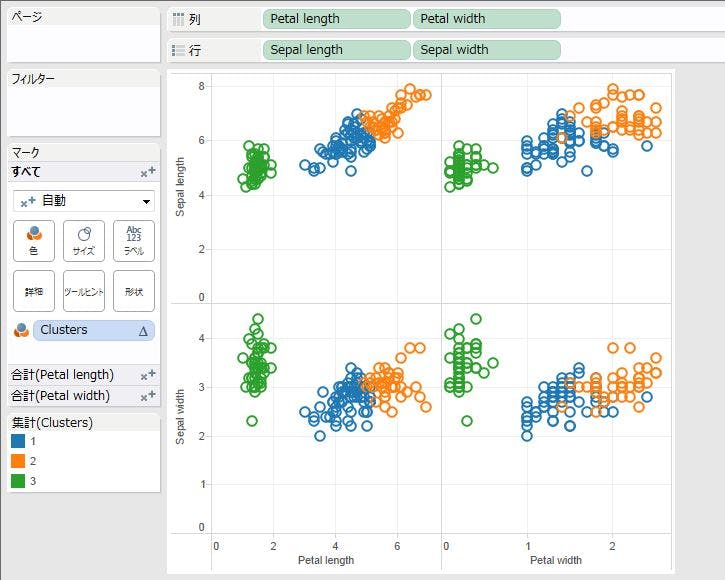
これで、サンプルと同じものを自分で作成することができました。
TableauでRに受け渡す変数を動的に変更する
次に、TablaeuからRに受け渡す変数を動的に変更できるようにカスタマイズしてみましょう。
今回のケースの場合、先ほど、指定したRコードでは、クラスタ数を3に固定していました。irisデータは、元々、3品種のデータですから、クラスタ数を3に指定するのは至極普通なのですが、実務上では、クラスタ数があらかじめ分かっているとは限りません。むしろ、そのケースは少ないかと思います。幾つかのクラスタ数を動的に変更しながら、クラスタリングができるように変更を加えていきます。これがまさに、前回、前々回でご紹介した、データアーティストの方でもクラスタリングの感度分析ができるようになるための設定になります。
メジャー欄から[Clusters]項目のメニューから「編集」をクリックします。
ここでの変更点は、以下の2つです。
・クラスタ数を変更できるようパラメータ化する
・作成したパラメータを式に埋め込む
まずは、パラメータの作成です。
「計算フィールド」ダイアログのパラメータ欄にある青字の「作成」をクリックします。「パラメータの作成」ダイアログが表示されますので、以下のように指定します。
名前: num_clusters
データ型: 整数
現在の値: 3
許容値: 範囲
値の範囲: 最小→1、最大値→10、ステップサイズ→1
ダイアログ画面では、以下のように表示されている筈です。
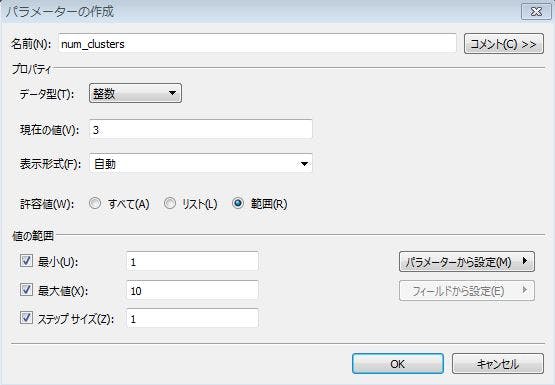
これで、クラスタ数をパラメータ化できました。次は、そのパラメータを式に埋め込む必要があります。「計算フィールド」ダイアログの式を以下のように修正します。
式: SCRIPT_INT(‘set.seed(42);result <- kmeans(data.frame(.arg1,.arg2,.arg3,.arg4),.arg5[1]);result$cluster;’,
SUM([Petal length]), SUM([Petal width]),SUM([Sepal length]),SUM([Sepal width]),[num_clusters])
最初の式からどこを変えたのかを見ていきましょう。まず、Rコードの{kmeans}関数に渡すクラスタ数を固定値の「3」から「.arg5[1]」に変更しています。また、それに対応するパラメータを指定するため、式の最後に「[num_clusters]」を追加しています。パラメータ[num_clusters]は定数ですので、Rコード中での渡し方は、「.arg5[1]」とする必要があるようです。
後は、パラメータを変更できるようにシートに追加します。メジャー欄の下にパラメータ欄が表示され、[num_clusters]が表示されていると思います。そのメニューから、「パラメータ コントロールの表示」をクリックします。パラメータコントロールが表示されたかと思います。
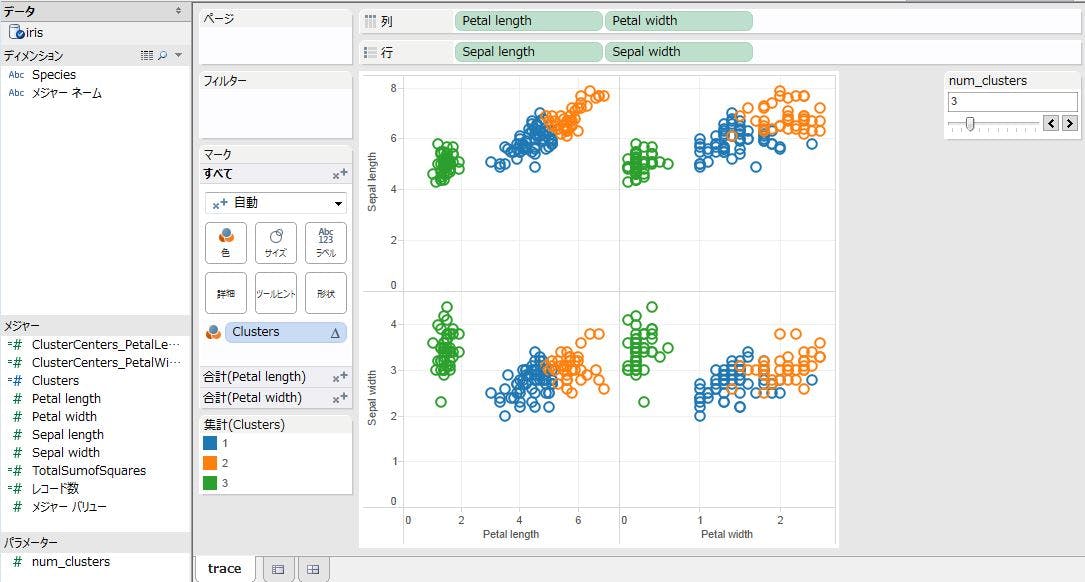
画面右にコントロールが表示されましたね。このコントロールからクラスタ数を4に指定しましょう。スライダーを利用して、クラスタ数を4にします。
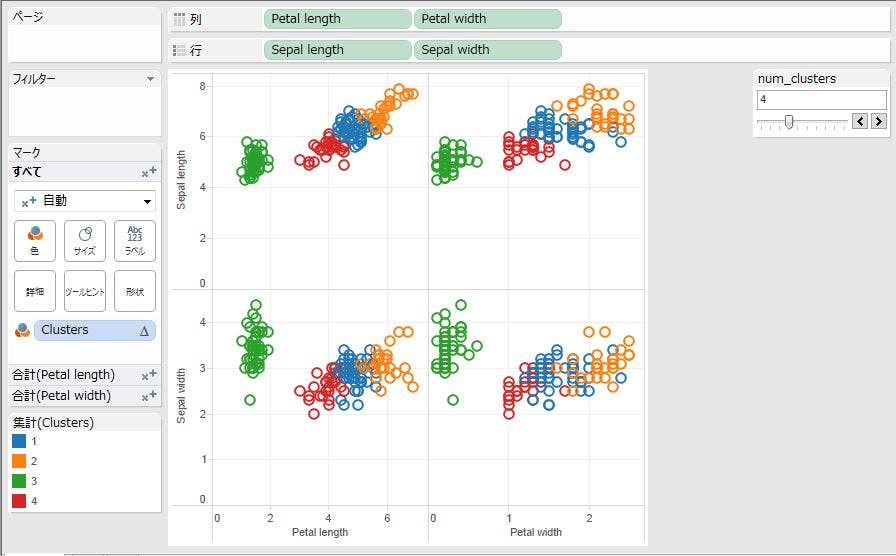
新しく4番目のクラスタが増え、赤色のクラスタがグラフに反映されました。
このように、パラメータを追加することで、スライダーを動かすだけで、新たなクラスタ数のクラスタリング結果が返ってくることがわかるかと思います。Rのコードをまったく見る必要はないですし、プログラムコードを書くのは敷居の高いデータアーティストの方でも簡単にクラスタリングの感度分析ができますね。
今回のまとめ
TableauとRとの連携は、よりシンプルな手法で、より綺麗なデータビジュアライゼーションができることを確認してきました。連載当初申し上げた通り、クラスタリング以外でも、Tableau-Rの連携環境を活用することは可能です。何が実現できそうなのかを色々と試行錯誤してみると良いかもしれません。
本連載が、ビジネス上のインサイトをより見つけやすい素敵なダッシュボード作成のお役に立ちましたら幸いです。
■参考リンク
http://www.tableausoftware.com/ja-jp/about/blog/2013/10/tableau-81-and-r-25327
http://www.tableausoftware.com/ja-jp/learn/whitepapers/using-r-and-tableau [Tableauホワイトペーパー]
【当記事は、ギックスの分析ツールアドバイザーであるYuu.Kimy氏にご寄稿頂きました。】
Yuu.Kimy
ギックス分析ツールアドバイザー。普段は、某IT企業にてデータ活用の検討/リサーチ、基盤まわりに従事。最近の関心事は、Rの{Shiny}パッケージのWebアプリ作成、Pythonによるデータ分析、機械学習等々。週末は、家事と子どもの担当をこなす(?)家庭にやさしいエンジニア(の端くれ)。
【個人ブログ】http://yuu-kimy-note.








