
この記事は GiXo アドベントカレンダー の 17 日目の記事です。
昨日は、Firestore のデータを TypeScript と Security Rules で安全に扱う話 でした。
Technology Div. の奥田です。前職ではC++を使ってCADを開発しており、GiXoには去年2019年9月に入社しました。クラウド開発歴は1年ほどです。今回は、そんなクラウド初心者の僕がとあるプロジェクトで開発・検証しているデータ基盤についてご紹介したいと思います。
本記事は以下の技術要素を含みます。
- GCP
- Github Actions
- Terraform
データ基盤の概要
絶えず生成される生データをBigQueryに取り込むデータ基盤を作成します。このプロジェクトには以下の制約があります。
- CSVを定期的に取り込む必要がある。
- BigQueryに取り込む際、重複を排除する必要がある。
- 処理が失敗した際にリトライする必要がある。
- 同様のシステムを量産する必要がある。
これらの制約を満たすために、下図のようなシステムを構築しました。
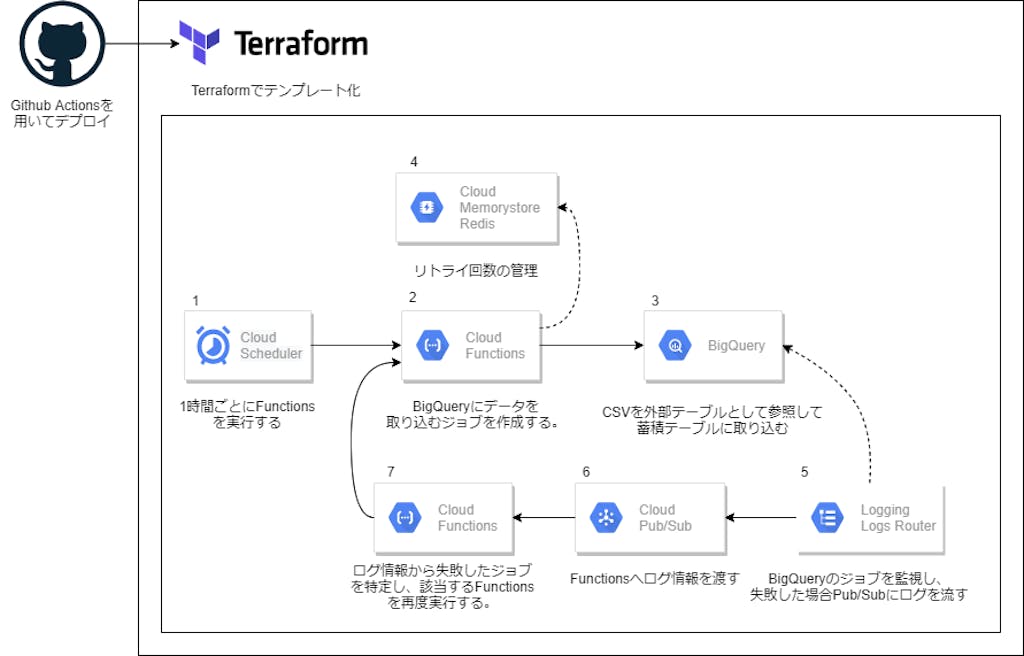
これからこのデータ基盤の詳細について解説します。
データ基盤の詳細
図中2のCloud Functionsで実行するPythonコードです。BigQueryから外部テーブルで参照しているパスにCSVを移動してから、蓄積テーブルにCSVを取り込むクエリを流しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
# CSVファイルを蓄積テーブルに蓄積するコード。 # 環境変数はTerraformから渡している。 from google.cloud import bigquery from google.cloud import storage from google.cloud.exceptions import NotFound import time import os import redis def run(request): # リトライ回数を管理するために、Redisに接続する。 # 必要な値は環境変数から取得する。この値はTerraformから渡される。 rc = redis.Redis(host=os.getenv("REDIS_HOST")) retry_key = f'retry_{os.getenv("SYSTEM_ID")}' bq_client = bigquery.Client() query = """ -- bar_extはCSVを参照する外部テーブル。 -- barは蓄積テーブル。 -- 蓄積テーブル内にCSVと重複するレコードがある場合、削除する。 DELETE FROM foo.bar WHERE (bar.COL1,bar.COL1,bar.COL3) in ( SELECT (COL1,COL2,COL3) FROM foo.bar_ext ) ; -- 蓄積テーブルにCSVデータを挿入する。 INSERT INTO foo.bar SELECT * FROM foo.bar_ext ; """ # Bodyにretryという名前のキーが存在する場合、リトライとして実行する。 request_json = request.get_json(silent=True) if request_json is not None and 'retry' in request_json.keys(): retry_count = int(rc.get(retry_key)) if retry_count == 0: print('リトライ回数が上限に達しました。') return "OK" rc.decr(retry_key) # Cloud LoggingからJob IDを検索できるようにするためBQ_JOBID_PREFIXを含める。 # また、どのFunctionsが発行したJobが失敗したか分かるようにFUNCTIONS_NAMEを含める。 query_job = bq_client.query(query,job_id_prefix=f'{os.getenv("BQ_JOBID_PREFIX")}___{os.getenv("FUNCTION_NAME")}___') return "OK" rc.set(retry_key,3) # 前回、ステージングディレクトリに移動したCSVがそのまま存在する。 # これを保管ディレクトリに移動する。 # 変換されたCSVをステージングディレクトリに移動する。 gcs_client = storage.Client() bucket = gcs_client.bucket(os.getenv("GCS_BUCKET_NAME")) # GCSのバケット名は環境変数から取得する。この値はTerraformから渡す。 blob_list = bucket.list_blobs(prefix=os.getenv("STAGING_PATH")) for blob in blob_list: bucket.rename_blob( blob,blob.name.replace( os.getenv("STAGING_PATH"), os.getenv("STORE_PATH"))) # 変換されたCSVをステージングディレクトリに移動する。 # ステージングディレクトリはBQから外部テーブルとして参照されている。 blob_list = bucket.list_blobs(prefix=os.getenv("CSVOUT_PATH")) for blob in blob_list: bucket.rename_blob( blob,blob.name.replace( os.getenv("CSVOUT_PATH"), os.getenv("STAGING_PATH")) # Cloud LoggingからJob IDを検索できるようにするためBQ_JOBID_PREFIXを含める。 # また、どのFunctionsが発行したJobが失敗したか分かるようにFUNCTIONS_NAMEを含める。 query_job = bq_client.query(query,job_id_prefix=f'{os.getenv("BQ_JOBID_PREFIX")}___{os.getenv("FUNCTION_NAME")}___') return "OK" |
図中7のCloud Functionsで実行するPythonコードです。図中2から発行するBigQueryのJobが失敗したときにLogs Router経由で実行されます。Job IDにFunction名を含めて実行しているので、そのFunctionをリトライします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# BigQueryでJobが失敗したとき、 # Job IDに環境変数BQ_JOBID_PREFIXの値が含まれている場合、この関数が実行される。 # 失敗したJobを発行したFunctionを再実行する。 # 環境変数はTerraformから渡される。 import redis import os import base64 import json import requests import re def run(event,msg): rc = redis.Redis(host=os.getenv('REDIS_HOST')) contents = json.loads(base64.b64decode(event['data']).decode('utf-8')) jobid = contents["protoPayload"]["serviceData"]["jobCompletedEvent"]["job"]["jobName"]["jobId"] # PubsubのIDを登録、また、すでに登録されている場合はFunctionが多重起動しているということなので処理を終了する。 if not rc.set(msg.event_id,1,nx=True, ex=1000): print('重複起動されているので終了します。') return "ok" # Job IDに関数名が含まれているので、その関数名を取得する。 match = re.search(f'{os.getenv("BQ_JOBID_PREFIX")}___(.+)___', jobid) function_name = match.group(0).replace(f'{os.getenv("BQ_JOBID_PREFIX")}___','').replace('___','') # Functionsを起動するためのトークンを取得する。 function_url = f'https://{os.getenv("DEFAULT_REGION")}-{os.getenv("PROJECT_NAME")}.cloudfunctions.net/{function_name}' metadata_server_url = 'http://metadata/computeMetadata/v1/instance/service-accounts/default/identity?audience=' token_full_url = metadata_server_url + function_url token_headers = {'Metadata-Flavor': 'Google'} token_response = requests.get(token_full_url, headers=token_headers) jwt = token_response.text # BigQueryで失敗したJobを発行したFunctionをリトライする。 # リトライ実行だということが分かるように、ボディーにretryというキーを含める。 body = {'retry': 'True'} headers = {'Content-Type': 'application/json', 'Authorization': f'bearer {jwt}'} requests.post(function_url,json.dumps(body),headers=headers) return "ok" |
CSVをBigQueryにインポートする方法としては、BigQuery Data Transfer Serviceを利用する方法も考えられますが、実際に利用してみたところエラーハンドリングの困難さから採用しませんでした。
ここで解説していない、その他リソースに関しては後のTerraformテンプレートにて解説します。
Terraformテンプレート
このプロジェクトでは図と同様のシステムを量産する必要があったのでTerraformを用いてテンプレート化しました。テンプレート内で利用する変数を.tfvarsファイルにまとめることで、量産が容易になります。
以下に、Terrafomから利用するファイルを示します。
terraform.tfvars : terraformテンプレートで利用する変数をここにまとめます。
|
1 2 3 4 5 6 7 8 9 10 11 |
PROJECT_NAME = "projectname" DEFAULT_REGION = "asia-northeast1" SYSTEM_ID = "foo" # リソース名の重複を避けるために含める文字列。 BQ_JOBID_PREFIX = "bq_job_prifix_" # BigQueryのJobを検索できるように、Job IDにこの文字列を付与する。 REDIS_HOST = "xxx.xxx.xxx.xxx" GCS_BUCKET_NAME = "bucketname" # 各所で利用するGCSバケット名 CSVOUT_PATH = "path/to/csv/output/directory" # CSVを保存するパス RAWDATA_PATH = "path/to/raw/data/file.dat" # 生データを配置するパス STAGING_PATH = "path/to/staging/directory" # CSVファイルをBigQueryで参照するためのステージング用ディレクトリ STORE_PATH = "path/to/store/directory" SERVICE_ACCOUNT_EMAIL = "xxx@yyy.iam.gserviceaccount.com" # 必要な権限を付与したService AccountのEmailアドレス |
.tfbackend : リソースの状態を保存するための.tfstateファイルを、CDを実現するためにGCSに出力するよう設定します。その設定をファイルに定義します。
|
1 2 |
bucket = "bucketname" path = "path/to/.tfstate" |
provider.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# .tfvarsに定義した変数をロードするには、ここで変数を定義する必要があります。 # 値は空でも大丈夫です。 variable "PROJECT_NAME" {} variable "DEFAULT_REGION" {} variable "SYSTEM_ID" {} variable "BQ_JOBID_PREFIX" {} variable "REDIS_HOST" {} variable "GCS_BUCKET_NAME" {} variable "CSVOUT_PATH" {} variable "RAWDATA_PATH" {} variable "STAGING_PATH" {} variable "STORE_PATH" {} variable "SERVICE_ACCOUNT_EMAIL" {} provider "google" { project = var.PROJECT_NAME region = var.DEFAULT_REGION } # backendをファイルからロードする場合は、このように空で定義することが可能です。 terraform { backend "gcs" {} } |
deploy.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
# 図中1のCloud Scheduler resource "google_cloud_scheduler_job" "job" { name = "scheduler_${var.SYSTEM_ID}" schedule = "0 */1 * * *" # 今回は1時間ごとに実行するように設定した。 time_zone = "Asia/Tokyo" attempt_deadline = "320s" retry_config { retry_count = 1 } http_target { http_method = "POST" uri = google_cloudfunctions_function.query_runner.https_trigger_url # 図中7のFunctionのURLを指定する。 oidc_token { service_account_email = var.SERVICE_ACCOUNT_EMAIL # 適切な権限を付与したサービスアカウントを指定しないと、Functionが実行されない。ログも出ず分かりにくいので注意。 } } } # 図中2のCloud Functionをデプロイするために、ファイルをzip化する。 data "archive_file" "query_runner_archive" { type = "zip" source_dir = "./query_runner" output_path = "./query_runner.zip" } # 図中2のCloud Functionをデプロイするために、zipファイルをGCSにアップロードする。 resource "google_storage_bucket_object" "query_runner_archive" { name = "query_runner_archives/query_runner_${var.SYSTEM_ID}.zip" bucket = var.GCS_BUCKET_NAME source = data.archive_file.query_runner_archive.output_path } # 図中2のCloud Function resource "google_cloudfunctions_function" "query_runner" { name = "query_runner_${var.SYSTEM_ID}" runtime = "python37" source_archive_bucket = var.GCS_BUCKET_NAME source_archive_object = google_storage_bucket_object.query_runner_archive.name trigger_http = true available_memory_mb = 128 timeout = 120 entry_point = "run" service_account_email = var.SERVICE_ACCOUNT_EMAIL region = data.google_redis_instance.redis.region environment_variables = { # コード内で利用する環境変数を渡す。 REDIS_HOST = data.google_redis_instance.redis.host SYSTEM_ID = var.SYSTEM_ID BQ_JOBID_PREFIX = var.BQ_JOBID_PREFIX GCS_BUCKET_NAME = var.GCS_BUCKET_NAME STAGING_PATH = var.STAGING_PATH STORE_PATH = var.STORE_PATH CSVOUT_PATH = var.CSVOUT_PATH } vpc_connector = "projects/xxx/locations/yyy/connectors/zzz" # Redisに接続するためのVPCコネクタを指定する。 vpc_connector_egress_settings = "ALL_TRAFFIC" } data "google_redis_instance" "redis" { name = "redisname" } |
デプロイは以下のコマンドで行います。
|
1 2 3 |
export GOOGLE_CREDENTIALS="path/to/gcp_credentials.json" terraform init -reconfigure -backend-config="./.tfbackend" terraform apply -var-file="terraform.tfvars" |
図中4,5,6,7のリソースは複数のシステムで共有するので別の.tfファイルで管理しています。.tfvarsや.tfbackend、provider.tfはほとんど共通のものを利用しているのでdeploy.tfのみ紹介します。
deploy.tf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
# 図中5のLogging Logs Router # BigQUeryのJobが失敗したときにログをPub/Subへ流す。 # リトライ対象のもののみをPub/Subへ流すように、ログはフィルタする。 resource "google_logging_project_sink" "pubsub" { name = "error_publisher" destination = "pubsub.googleapis.com/projects/${var.PROJECT_NAME}/topics/error_retry" # 抽出したログをPub/Sub トピックに流す # 正規表現を用いてJob IDにBQ_JOBID_PREFIXが含まれるログをフィルタする。 filter = "(protoPayload.serviceName: BigQuery AND severity: \"ERROR\" AND protoPayload.methodName: jobcompleted AND protoPayload.resourceName =~ \"${var.BQ_JOBID_PREFIX}___.+___\")" unique_writer_identity = true } resource "google_project_iam_binding" "log-writer" { role = "roles/pubsub.editor" members = [ google_logging_project_sink.pubsub.writer_identity, ] } # 図中4のRedis resource "google_redis_instance" "redis" { name = "redisname" memory_size_gb = 1 tier = "STANDARD_HA" } # FunctionsやCloud RunからRedisに接続できるように、VPCコネクタを作成する。 resource "google_vpc_access_connector" "vpcconn" { name = "vpcconn" region = google_redis_instance.redis.region ip_cidr_range = "10.126.0.0/28" network = "default" } # 図中7のCloud Functionをデプロイするために、ファイルをzip化する。 data "archive_file" "function_archive" { type = "zip" source_dir = "./retry_function" output_path = "./retry_function.zip" } # 図中7のCloud Functionをデプロイするために、zipファイルをGCSにアップロードする。 resource "google_storage_bucket_object" "archive" { name = "retry_function.zip" bucket = var.GCS_BUCKET_NAME source = data.archive_file.function_archive.output_path } # 図中7のCloud Function resource "google_cloudfunctions_function" "function" { name = "retry_function" description = "Managed by terraform" runtime = "python37" source_archive_bucket = var.GCS_BUCKET_NAME source_archive_object = google_storage_bucket_object.archive.name available_memory_mb = 128 timeout = 120 entry_point = "run" service_account_email = var.SERVICE_ACCOUNT_EMAIL event_trigger { event_type = "providers/cloud.pubsub/eventTypes/topic.publish" resource = "projects/${var.PROJECT_NAME}/topics/error_retry" } environment_variables = { REDIS_HOST = google_redis_instance.redis.host PROJECT_NAME = var.PROJECT_NAME DEFAULT_REGION = var.DEFAULT_REGION BQ_JOBID_PREFIX = var.BQ_JOBID_PREFIX } vpc_connector = google_vpc_access_connector.vpcconn.id vpc_connector_egress_settings = "ALL_TRAFFIC" } |
GCSバケットやBigQueryのテーブルなどのリソースもTerraformで管理することができますが、terraform destroy等のコマンドで誤って削除してしまうリスクが高いのでTerraformでは管理していません。
ちょっとした黒魔術
詳細は割愛しますが、実際には変数を.tfvarsファイルのみに集約するために、.tfvarsファイルから.tfbackendファイルや、環境変数定義用のシェル生成を行っています。.tfvarsファイルはシンプルなので、シェルスクリプトで簡単にパースできます。
|
1 2 |
# PROJECT_NAMEの値を取得する PROJECT_NAME=`grep "\s*PROJECT_NAME\s*=" terraform.tfvars| grep -o "\".*\"" |
Github Actions
CDを実現するために、Github Actionsを利用しています。
./github/workflows/ 内にyamlファイルを置いておくと、ファイルに記述したコードをGithub上で実行させることができます。このシステムでは、deployブランチにプッシュされたときに、terraformを使ってリソースのデプロイが自動的に行われるように設定しています。また、事前にsecretsにサービスアカウントキーを登録することで、安全にサービスアカウントが利用できます。
./github/workflows/deploy.yml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
name: Deploy on: push: branches: - deploy env: SYSTEM_ID: xxx GOOGLE_CREDENTIALS: ${{secrets.GCP_SA_KEY}} PROJECT_NAME: xxx GCS_BUCKET_NAME: xxx jobs: delivery: runs-on: ubuntu-latest steps: - name: Checkout the repository uses: actions/checkout@v1 - name: Setup Terraform uses: hashicorp/setup-terraform@v1 - name: GCP Authenticate uses: GoogleCloudPlatform/github-actions/setup-gcloud@master with: version: '273.0.0' service_account_email: xxx@yyy.iam.gserviceaccount.com service_account_key: ${{secrets.GCP_SA_KEY}} - name: Configure docker to use the gcloud cli run: gcloud auth configure-docker --quiet - name: Deploy run: | cd ${GITHUB_WORKSPACE}/path/to/terraform terraform init -reconfigure -backend-config="./.tfbackend" # Cloud FunctionsはTerrafromでコードの変更を検知して更新できないのでapplyする前にdestroyすることで強制的に更新する。 terraform destroy -target=google_cloudfunctions_function.query_runner -auto-approve terraform apply -var-file="terraform.tfvars" -auto-approve |
Cloud Functionsのコード変更をTerraformで検知して更新することができないので、Github Actionsからdestroyして更新していますが、コードのハッシュ値を利用して変更を検知および更新することができるようです。
https://github.com/hashicorp/terraform-provider-google/issues/1938
まとめ
今回は、僕が開発しているデータ基盤の話を技術面にフォーカスして書いてみました。実際のコードはもっと複雑で量が多いのですが、シンプルにするためにかなり削ったり改変したりしました。大変でした・・・ですので、ニッチな内容が多いかと思いますが、どこかの誰かに少しでも参考にしていただければ幸いです。
明日は「SHAP Values で 機械学習を「解釈」する」を公開予定です。
Yuki Okuda
Technology Div. 所属
GiXoでエンジニアをやっています。







