
本記事は、株式会社ギックスの運営していた分析情報サイト graffe/グラーフ より移設されました(2019/7/1)
固定長データは「電文」と呼ばれ、昔から使われていた
分析対象となるデータ形式として、CSVに代表される区切り文字ファイル形式、インターネットでのデータのやり取りで多く使われているJSON、XML形式などがあります。しかし、昔はこれらのデータ形式ではなく、”固定長データ”でデータのやり取りを行う事が一般的でした。今回は、固定長データについてご紹介したいと思います。
昔の通信速度は遅く、記憶容量は高価だった
固定長データの内容説明に入る前に、固定長データが一般的に使われていた時代について説明したいと思います。
固定長データは、パソコンが普及する前からコンピュータ間のデータ通信の手段などに使われてきました。当時は、通信速度が遅く、文字情報を送るのがやっとの時代でした。また、コンピュータの記憶容量も非常に小さく、大掛かりな磁気テープ装置に情報を記憶していました。そのため、限りある資源を有効に活用するためにCSVデータ形式などは導入できませんでした。
固定長データは桁数でデータ項目を判断する
固定長データは、1件の情報の文字情報の桁数が決まっています。その決まった桁数の中にデータ項目が決まった位置に隙間なく配置されています。そして、桁数からデータ項目を判断できるため、CSVデータのように1件の情報ごとに改行文字が入るとは限りません。
下記の売上情報を例にすると、1件の情報は33桁(バイト)固定となっており、1~8桁は売上日、9~12桁は売上時間、13~15桁は伝票番号、16~20桁は商品コード、21~29桁は販売金額、30~33桁は割引率と決まった場所にデータ項目が配置されています。また、販売金額などプラス、またはマイナスが入るデータ項目では符号の位置も固定され、決められた桁数になるようにゼロ詰めされます。(俗称:前ゼロ) さらに小数の位置も固定されていますので、割引率の4桁のうち、前2桁を整数領域、後ろ2桁を小数値のように扱っています。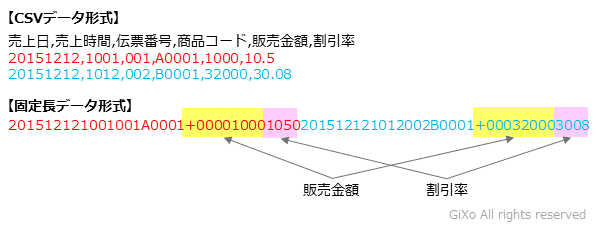
固定長データは、昔からコンピュータ間のデータのやり取りで行われ、この情報の事を「電文」と呼んでいました。今でも、古くからコンピュータを導入している金融系の企業では、データの事を「電文」と呼んでいる場合があります。
固定長データのデメリット
固定長データは、隙間なく情報を詰め込めるため、データ通信や記憶の面で優れている面があり、当時のシステム開発言語であるCOBOL(コボル)言語が、この固定長データに特化していたため、非常に便利でした。しかし、情報量が多くなるにつれて、固定長データでの運用は厳しくなってきました。
固定長データは、全てが桁数で決まっています。そのため、データ項目を増やしたり、データ項目の桁数を増やすことは、システムの大幅な修正になる場合があります。もちろん、固定長データの初期設計時にも未来の拡張性を考慮して、1件の情報の文字情報の桁数の中に予備領域を持たせる場合もありますが、予備領域では、現代の情報量の拡大に付いていくことは出来ません。
予備知識:2000年問題は固定長データが原因の1つだった!
1990年より前のデータの受け渡しで使用する固定長データでは、可能な限り文字情報を減らした結果、日付情報を6桁で持たせることが一般的でした。具体的には「1981年12月12日」を「811212」のように持たせていました。そして、この日付形式を固定長データだけでなく、DBにも登録していました。そのため、この日付形式で2000年以降になった場合、取引日の前後判定が2000年を挟んで逆になる、年齢、契約期間の計算ができなくなるなどの問題が発覚し、システムの大改修が行われていました。
実際には、固定長データの予備領域に年の上2桁を持たせたり、システム内で年の上2桁を付加するなどの対応を行い、2000年を乗り越えることができました。
データ分析用語:索引




