
目次
HeteroServerはオンプレ分析データベースの導入のハードルを下げる新たな選択肢
ビッグデータの分析データベースと言えば、Amazon Redshift や Google BigQuery などのクラウドデータベースが一般的になりつつあり、Oracle Exadata などの今まで分析データベースとして使われてきたオンプレデータベースからのシステム移行が進んでいます。そんな中、斬新なテクノロジでオンプレデータベースに新たな風を引き込みそうなHeteroDB(ヘテロDB)社の「HeteroServer」というソリューションに触れる機会ありましたのでご紹介します。
HeteroServerとは
ミドルレンジ専用の分析データベース
分析データベースにはデータサイズによって運用に耐えられる限界が決まっています。1つのトランザクションデータが10GB程度(1億行程度)なら1台のハイスペックなサーバーで動かすことも可能です。しかし、1台で処理できる限界を超えた時、複数台で処理を負荷分散させるクラスタリングにより大量データでも耐えられるようにしています。今回、ご紹介するHeteroServerは、この1台構成の一般的なデータベース(ローエンドレンジ)と複数台構成の専用データベース(ハイエンドレンジ)の間に位置するミドルレンジ専用の分析データベースになります。
GPU + NVMe SSD による超並列処理
従来の方法ではデータベースの処理性能がCPU処理性能や記憶媒体(ハードディスク)の入出力速度に依存していました。そのため、データベースの処理性能を上げるためには複数台数での負荷分散という方法しかありませんでした。しかし、HeteroServerはこの2つの問題をGPUとNVMe SSDに置き換えることで1台のサーバーでも大量データを処理できるようにしています。
HeteroServerはPostgreSQLの拡張機能であるPG-Stromによって、通常CPUで行われる検索処理をGPUで代行しています。近年、GPUは Machine Learning などでも注目されているように大量のコアでの超並列処理に特化しています。HeteroServerも同様に大量データを大量のGPUコアで超並列処理することでCPUより速く処理することができます。(GPUで処理をさせるためにSQL命令文の変更などは特別な操作は必要ありません)
しかし、GPUの処理速度が速くてもデータの入出力が遅くては意味がありません。そこでNVMe Stromの技術によってGPUとNVMe SSDがダイレクト通信することで超高速なデータ入出力が可能になりました。その結果、同様のハードウェア構成で通常のPostgtreSQLと比較してHeteroServerは約5倍の処理性能を出すことが可能です。(ハードディスクドライブ(HDD)とNVMe SSDとの単純な速度比較はこちら)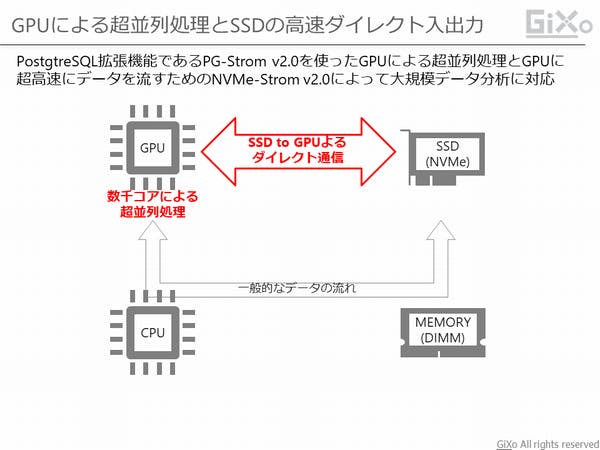
HeteroServerの強み
コストも場所も従来の分析データベースの1/10
オンプレ分析データベースもっとも大きなハードルとして導入コストがあります。ハイエンドレンジのOracle Exadata などは専用のハードウェアを複数台組み合わせて1つのデータベースとして機能しています。そのため、最小構成でも数千万円の初期費用は掛かるらしいです。また、ハードウェア自体も巨大になり、サーバーラックと呼ばれるサーバー専用の棚が必要になります。
しかし、HeteroServerは既製品のCPUやGPU、NVMe SSDを組み合わせる事でハイエンドレンジのオンプレ分析データベースと比較して1/10程度に初期費用を抑える事が可能です。また、HeteroServerのサーバーサイズは1Uと呼ばれるサーバーラック1段分の大きさですので、サーバーラックに空きがあればHeteroServerを入れるだけですし、置く場所さえあれば巨大なサーバーラックを導入する必要もありません。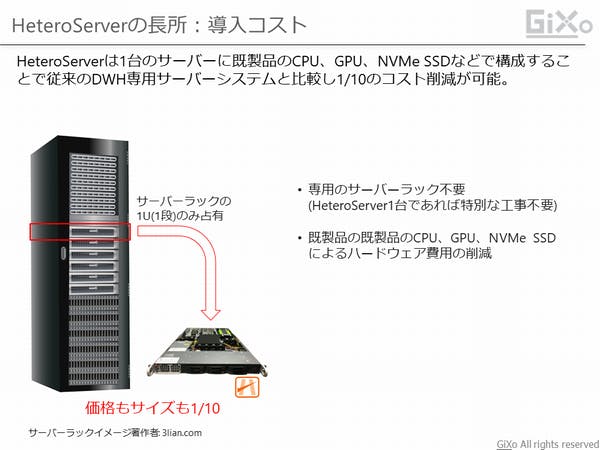
テーブルチューニング不要
一般的なデータベースの場合、テーブルの検索処理速度を改善するためにデータ項目にインデックスと呼ばれる機能を追加したり、テーブル内のデータを分散配置するなどのテーブルチューニングが必要になります。これらの作業には専門のスキルが必要になり、システム要件やデータ量によって変わってくるため非常に大変な作業です。
しかし、HeteroServerはインデックス作成やデータ分散などのテーブルチューニングは不要です。なぜならHeteroServerはGPUによる超並列処理とNVMe SSDのダイレクト通信による超高速データ入出力で全件検索を行っているからです。一般論からすれば全件検索は悪しき処理方法のためインデックス作成やSQL命令の再作成などでチューニングするのですが、HeteroServerはテーブル内の全てのデータ項目で高速な検索処理が可能です。また、全件検索ですのでインデックスが効かない文字列の部分一致検索でも高速に処理できます。
柔軟な機能拡張
PG-StromはPostgtreSQLの拡張機能、HeteroServerには一般的なLinux系のOSが入っています。そのため、PostgtreSQLの拡張機能追加やLinuxで動くソフトウェア追加などが普通に行えます。専用のデータベースシステムでは大きな機能拡張は行えないことが多いですが、HeteroServerはPostgreSQLにPostGISを機能追加して位置情報分析を行ったり、GPU処理を行う Machine Learning をLinux上で実行する事も可能です。
注:現段階ではPostGISはCPU処理ですが、早い時期にPG-StromがPostGISに対応するらしく、その対応よってGPU処理が行える予定との事です
HeteroServerの弱み
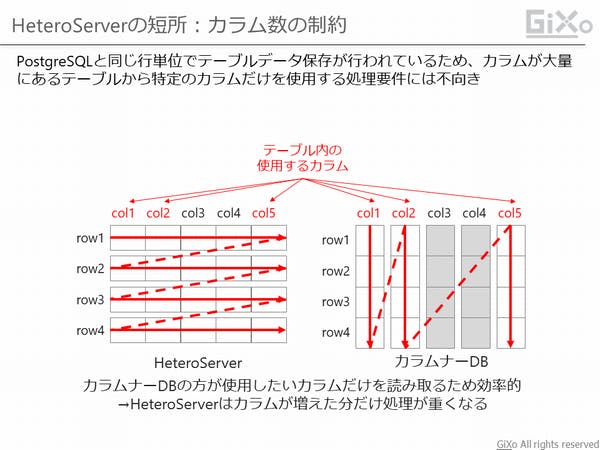
分析データベースとして非常に高性能なHeteroServerですが、弱い部分も幾つかあります。特に弱いのが大量のデータ項目を持ったテーブル検索です。
HeteroServerは一般的なデータベースのPostgtreSQLを使っています。そのため、テーブル内のデータは行単位で登録しています。行単位で登録することでデータ追加は高速、かつ、複数の処理を並列で実行する事が可能です。しかし、大量にあるデータ項目から特定のデータ項目だけを使用した場合でも全データ項目を処理対象にしてしまうため非効率になってしまいます。
RedshiftやBigQueryなどのクラウド分析データベースでは、テーブル内のデータを列単位で登録するカラムナー型の保存形式のため、テーブル内のデータ項目数の数に関係なく、特定のデータ項目だけを処理対象にするため効率的です。
実際に検証した結果では、使用するデータ項目だけに絞ったテーブルではHeteroServerとRedshift(ds2.xlarge x 3node / ソートキーなし)がほぼ同じ処理速度でしたが、使用しないデータ項目を持ったテーブルではデータ項目の数(データ量)に比例してHeteroServerの処理性能が落ちる結果になりました。
ただ、今回は未検証でしたが「インメモリ列キャッシュ」という機能がPG-Stromにあるらしく、サーバーメモリを使って一時的にカラムナー型でデータ保持できるらしいです。それ程大きくないテーブルサイズならインメモリ列キャッシュを使うことで処理速度改善が行えたかもしれません。
HeteroServerはオンプレ分析データベースとして期待できる
現在、HeteroServerの中核であるPG-Stromのバージョンは2.0で、旧バージョンから作り代えたばかりとの事です。そのため、処理速度改善や機能拡張などを検討中との事です。また、ハードウェア面でもGPUやNVMe SSDなどの技術進歩によって処理速度改善や扱えるデータ量の拡大が見込まれます。
クラウド分析データベースが処理性能やコスト面でHeteroServerより有利です。しかし、クラウドサービスを使えない企業や団体にとって、今まで高価なオンプレ分析データベースしか選択肢がありませんでしたが、HeteroServerの登場によって新たな選択肢が増えたと思います。







