
データレイクサービスを賢く安く使うポイント
前回の連載ではクラウドサービス上のデータレイクサービスについてご説明しました。その中でデータレイクサービスはデータベースサービスのように起動時間による課金が発生しない分、データ参照時の参照先のデータファイルのサイズによる課金が発生するため、使用料が高額になる危険性をご説明しました。また、データレイクサービスは、非常に簡単にデータファイルの参照が行えるのですが、多少のデータファイルの制約が発生する場合があります。今回はこれらデータレイクサービス特有の問題の解決方法をご説明します。
※データレイクサービスとして、AWSの Amazon Athena(以下、Athena)と Azure Data Lake Analytics(以下、Data Lake Analytics)の2つについてのみご説明させていただきます
クラウドストレージのフォルダ管理方法
クラウドサービスではクラウドストレージ上のデータファイルをフォルダ単位で指定できます。(Data Lake Analytics はファイルパスの部分一致も可能) そのため、クラウドストレージのフォルダ構成こそがデータレイクサービスが賢く使えるかの肝になってきます。そして、様々なシーンを想定した時、以下のフォルダがデータレイクサービスで扱いやすいという結果に至りました。これから、このフォルダ構成になった経緯についてご説明します。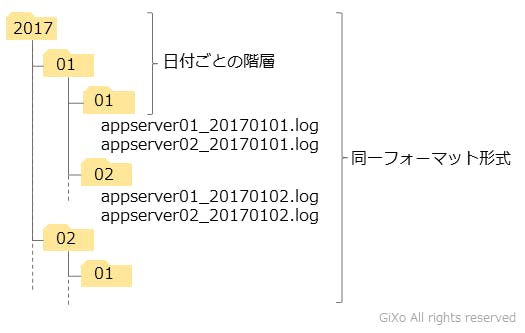
データフォーマットごとにフォルダを分けよう
クラウドストレージのフォルダ単位でデータレイクサービスのデータ参照をするという事は、フォルダの中の全てのデータファイルが1種類のデータとして扱われます。そのため、フォルダ内の複数のファイルの内、1つでも異なるデータフォーマットのファイルが含まれていた場合、データレイクサービスのエラーによってフォルダ内の全てのファイルが読めない、または異常値になってしまう場合があります。
これらの事が起きないようにフォルダ内のデータファイルは同じデータフォーマットにする必要があります。(前提条件としてデータファイル内のデータフォーマットは統一されている)
期間ごとのフォルダ階層に分けよう
クラウドストレージのフォルダ内が同一のデータフォーマットの場合、システムとして問題なくデータ参照が行えます。しかし、1つのフォルダに大量のデータファイルが集まった場合、そのフォルダをデータ参照した時のデータレイクサービスの使用料が高額になることが予想されます。そのため、上記の巣のように年、月、日のフォルダを階層ごとに作り、データファイルを小分けすることお勧めします。
この様に期間ごとのフォルダ構成にしていれば、「昨日のデータからシステムエラーを探す」や「前月のアクセス先ごとの集計を分析」などの特定の期間のデータ参照を行う場合、データレイクサービスから必要な期間のフォルダを指定できるため、不要なデータファイルの参照を減らすことができます。また、参照先のデータファイルのサイズが小さければ、処理時間も短くて済みます。
将来的にデータレイクサービスのファイルサイズが膨大になりそうな場合、期間ごとのフォルダ構成にデータファイルが振り分けられるようにシステム構成を行うことをお勧めします。
クラウドサービスの使用料の監視機能を使う
通常の運用を想定した時、データレイクサービスはデータベースサービスより安価に運用できると思います。しかし、システム拡張や異状処理で急激にログファイルが増えた場合などよって、気づかないうちに使用料金が増えている場合が考えられます。そのため、クラウドサービスにある使用料の監視機能を使うことをお勧めします。
AWS、Azure共に使用料監視機能があり、任意で設定した使用料を超えた場合にメールなどで知らせてくれる機能があります。これらを使うことでクラウドサービスの請求金額が巨額になることを回避することができます。また、AWS CloudWatch は、Athena などのサービス単位でピンポイントで監視できるため、コスト管理がAWSアカウント+サービスごとに行えるため非常に便利です。
データレイクサービスは万能ではない
データレイクサービスは、Hadoopフレームワークサービスのようにプログラミングを行う必要はなく、SQL類似の命令だけでクラウドストレージ上のデータファイルをクイックに参照できるため、容易にデータレイク環境が構築できます。しかし、便利にした分、Hadoopフレームワークサービスのように細かい要望に応える柔軟性が失われました。
データレイクサービスは、CSVのような区切り文字ファイル、JSONファイルなどに対応していますが、その中でも扱えるデータファイルに制限があります。例えばCSVファイルの先頭行にタイトル行がある場合やUTF-8以外の文字コードの場合は扱えないことがあります。(Athenaリリース直後はダブルクォーテーションで括られたCSVデータフォーマットが扱えませんでしたが、今年の春ごろに改善されました) これらの制約については、今後、データレイクサービスの機能追加などによって解消される場合がありますが、期待はしない方が良いと思います。
そのため、データレイクサービスを導入する場合は、データレイク本来の「後から溜まったデータファイルを確認する」ではなく、ある程度、溜まった段階でデータレイクサービスの動作確認は絶対に必要です。そして、データレイクサービスで対応できないデータフォーマットの場合、データフォーマットを変えるか、Hadoopフレームワークサービスの導入を検討する検討する必要があります。
最後に
今まで蓄積したデータファイルに対して、データレイクのシステム導入を検討していましたら、とりあえずデータレイクサービスを使ってみてください。データレイクサービスはクイックに始められ、使わなければデータレイクサービスの使用料は一切かかりません。
今まで連載してきた記事を読んで頂き、これまで蓄積してきたデータの山が、宝の山になることを願っております。
関連記事
- データレイクとクラウドサービス ~①データレイクの今までをおさらい~
- データレイクとクラウドサービス ~②クラウドサービスが支えるこれからのデータレイク~
- データレイクとクラウドサービス ~③クラウドストレージの賢い管理方法~ (本稿)






