
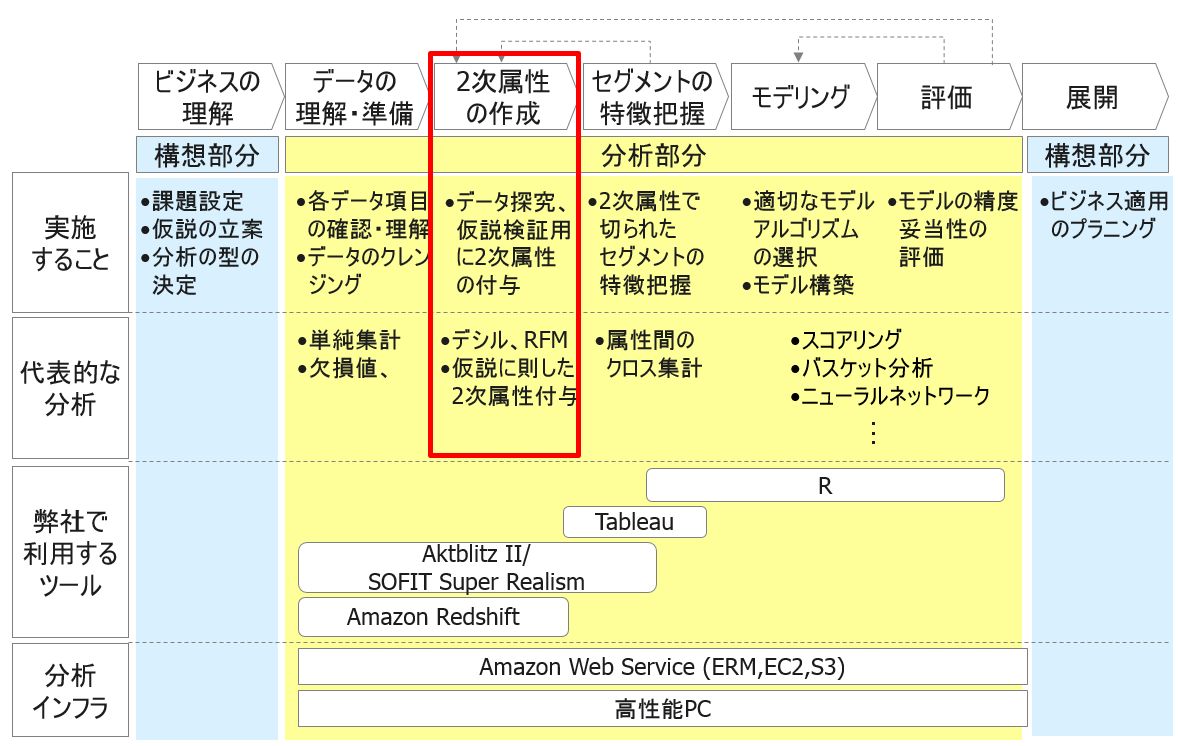
ギックスならではの分析プロセス 「2次属性の作成」
前回は分析プロセスの最初の段階となる「ビジネスの理解」と「データの理解・準備」のプロセスについてご説明しました。今回は、いよいよギックスデータ分析体系ならではの分析プロセスであたる「2次属性の作成」についてです。ギックスのビックデータ分析体系では以下の赤枠の部分に相当します。
まず最初に、2次属性の正確な定義から紹介しましょう。
「仮説を検証、もしくは何か起こった事象の原因を知るために、トランザクションデータ(=顧客の購買明細データ)から新たに顧客に紐づける属性」となります。顧客データには、もともと性別、年代、職業、居住地域などの顧客に固有の属性データがついていますが(1次属性に相当)、それとは別にトランザクションデータから新たにつける属性ということで2次属性データと呼んでいます。
2次属性付けとは同じグループに同じシールを貼ること
この説明、普段からデータを扱っている人にはピンとくるかもしれないですが、データ分析になじみのない人にはわかりにくいかもしれません。もっと平易に説明してみます。
そもそも、トランザクションデータ(=顧客の購買明細データ)は「誰が」「何を」「いつ」「いくらで」購入したかという巨大な数値の羅列のデータです。そのまま眺めていても人間では全く解釈できないものです。それを解釈するためには、共通の特徴を持つ「人」や「製品」に対して、同じグループに属しますという印(しるし)をつけてあげて分別してあげる必要があります。同じグループの人や製品に同じシールをペタペタと貼ってあげるイメージが近いかもしれません。その共通の特徴を持っている人に同じシールを貼ってあげることが2次属性を付けるということになります。
例えば、製品に対してはその価格帯に応じて、「高級製品」「普及製品」「廉価版製品」というシールを貼ることは可能ですし、それを好んで購入している人に対しても、「高級品嗜好」「普及品嗜好」「廉価版嗜好」というシールを付けてグルーピングすることも可能です。またキャンペーンで販売した製品に対して「キャンペーン製品」というシールを貼っておけば、そればかり好んで購入している人に対して、「キャンペーン反応者」というシールを貼ることもできます。
このようにシールを貼っておくとで、同じシールを貼られている人がどのような行動をしているかを理解することができ、同じシールを貼られている製品がどう売れているかが把握できるようになります。仮説とは、「特定のグループの人が何か特別な行動をしているのではないか」とか、「特定の製品が何か特別の売れ方をしているのではないか」と考えることですので、その「特定のグループの人」や「特定の製品」というものをうまくくくれるシールの貼り方さえ決めてあげれば仮説を検証する準備が整うことになります。
ビッグデータでもシールを簡単に貼ったり剥がしたりできる
このシールをペタペタ貼るという2次属性という考え方ですが、この手法自体は決して目新しいものではありません。むしろこれまで分析したことある方は何かしら属性付けをしているのではないかと思います。では、なぜ我々はこの2次属性付けを今ここまで強調しているのでしょうか。
それは、テクノロジーの進歩により、このシールを貼るということが、ビックデータに対して非常に簡単にできるようになっているからです。ペタペタ貼ったり剥がしたりという試行錯誤が簡単にできるようになっています。まさに企画する人のアイデアと仮説立案能力さえあれば、シールを貼って、その貼られた人たちがどのように動いているかを見ることができるようになっています。その試行錯誤が可能になったことが、まさにビックデータ時代の恩恵だと我々は考えています。具体的なシールの貼り方は、ギックスのビッグデータ分析体系の「弊社で利用するツール」の部分を説明する際にお話していくようにします。
今回は2次属性とはいったいどういうものかということをご説明しました。次回はその2次属性を付けた後のセグメントの特徴把握という内容について紹介していきます。




