
本記事は、株式会社ギックスの運営していた分析情報サイト graffe/グラーフ より移設されました(2019/7/1)
目次
分析結果チェックは、ランダムに数か所のデータをチェックすれば良い訳じゃない!
分析結果チェックでは、分析元データの件数、合計などを分析結果と違う方法で算出し、分析結果と比較することは頻繁に行っていると思います。しかし、分析結果として100件以上の件数が出力された時、その全てに対して比較しているのでしょうか?
大抵の分析業務では、大量の分析結果から幾つかをサンプリングしてチェックしていると思います。しかし、そのサンプリングは、的確でしょうか? 今回は、大量の分析から的確なサンプリングを行うチェックポイントをご紹介します。
しきい値前後をチェックする
しきい値の前後をチェックするとは、抽出条件などで確実にデータを取得したかをチェックする事です。大量データの分析では、分析元データから期間や区分などからデータを絞って、分析処理を行うことが多いです。この時、抽出条件の前後のデータを確認して、分析対象になっているかを確認します。
下記の例は、ユーザーごとの売上情報のデータ分析です。この分析元データから年齢算出を行い、そこから若者(30歳未満)を分析対象としています。2016年1月31日を分析の基準日にした場合、1986年2月1日以降の誕生日の30歳未満のユーザーが分析対象となります。逆に1986年1月31日以前の誕生日の30歳以上のユーザーは分析対象外になります。よって、分析元データからこの2つの誕生日のデータをそれぞれ1件ずつ確認することで抽出条件が正しいことを証明することができます。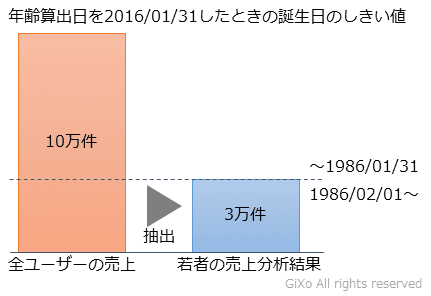
しきい値前後のチェックは、数値項目をレンジによってカテゴリ変換している場合にも有効です。(参考:データ分析のレンジによって数値情報をカテゴリに変換する) 抽出条件と同様にレンジのしきい値前後を確認します。
下記の例は、商品単価の価格帯をレンジによってカテゴリ変換しています。分析元データから低価格帯の上限(1,999円)、中価格帯の下限(2,000円)、中価格帯の上限(9,999円)、高価格帯(10,000円)の4つの商品単価のデータをそれぞれ1件ずつ確認することでカテゴリ変換条件が正しいことを証明することができます。
集計結果の最大値・最小値をチェックする
集計結果の最小値・最大値をチェックすることで異常データを見つけることができます。どんなに分析処理が正しくても、分析元データに重複や想定外の異常値があった場合、分析結果も正しい結果になるとは限りません。これらの異常データを見つけるために集計結果の最大値、または最小値となった分析元データを確認します。
最大値、または最小値のデータに限定する理由として、異常データが集中した結果、ほかの集計結果データに比べて集計結果が偏ってしまった場合があります。このように異常データが集中していれば、原因となったデータを発見できる確率が増えるためです。
また、単純に最大値、または最小値が、想定の範囲であるかを確認するだけでも十分効果があります。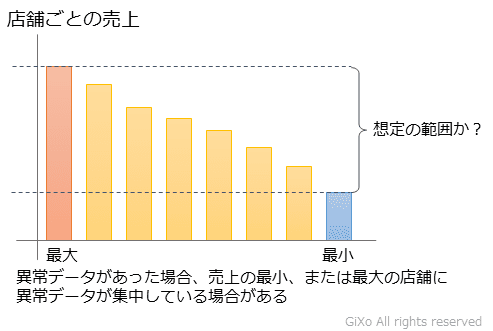
分析結果チェックは理論的、かつ無駄なく行う
今回ご紹介したチェックポイント以外にもデータ構造やデータ型などのチェックポイントがあります。分析結果チェックは、チェック数が多ければ良い訳ではありません。チェック数が多くても重要なチェックポイントを取りこぼしていたら無意味です。分析元データや分析結果データ、分析処理方法を考慮し、理論的にチェックポイントを列挙して、無駄なく行う必要があります。




