
本記事は、株式会社ギックスの運営していた分析情報サイト graffe/グラーフ より移設されました(2019/7/1)
目次
コンピュータにおけるテキストとデータの違いとは?
本日は「テキスト」という言葉を解説します。そもそも「テキスト」とは、wikipediaの記事を引用すると
文章や文献のひとまとまりを指して呼ぶ呼称。 言葉によって編まれたもの、という含みを持つ語で、織物(Textile テクスタイル)と同じくラテン語の「織る」が語源である。
引用元:wikipedia
という語源を見ることができますが、ここから転じてコンピュータにおいての「テキスト」とは「文字データ」という言葉で表すことができます。文字のデータと文字ではないデータにはどのような違いがあるのでしょうか?
コンピュータが扱うデータは2種類に分けることができる
以下に二つのデータ①②を用意しました。
データ①:
こんにちは
データ②:
![]()
どちらも人間の目には「こんにちは」に見えますね?しかしコンピュータにとっては①と②はまったく別のデータなのです。ちなみに「テキストは①」です。②はテキストではありません※1。実は②は画像データなのです。ためしに①と②をそれぞれマウスで選択してみてください。①は文字ごとに選択できると思います。選択した文字をコピーしてメモ帳に貼り付けることもできるでしょう。でも②ではその操作を行う事ができません。①のデータはコンピュータが「文字」として扱っているのです。このようにコンピュータは、自身がデータを取り扱う上で「これは文字だ!文字として処理しよう!」または「文字ではないからそれなりの処理をしよう!」という明確な区別を行っているのです。
コンピュータにおける「文字」とは?
ではその「文字である/文字ではない」という判断基準は何なのでしょうか?それには「文字コード」の存在が重要です。文字コードとはコンピュータ上で文字を扱うにあたっての表現を定めた世界的な規約です。コンピュータは「文字コードのルールに則ったデータ」を「テキスト=文字データ」として扱います(文字コードについてのより詳しい説明はこちら)。
ちなみに上記①の「こんにちは」はコンピュータの内部では2進数として以下のように表現されています(文字コードはShift-JISです)。
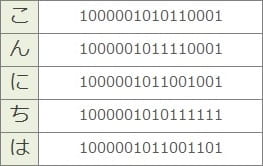
テキストの特徴はデータ量が少ないこと
ちなみに上記①のデータ(テキスト)は10バイトですが、上記②のデータ(画像)は2,812 バイトあります。同じ内容を伝えたいのであればテキストデータのほうが圧倒的にデータ量が少なくてすむのです。逆にデータサイズが同じであれば、テキストファイルのほうがよりたくさんの情報量を格納することができます。これはテキストデータの優れた特徴の一つです。我々がデータ分析において分析対象とするデータもほとんどはテキストデータです。
※1…上記②のような「テキストではないデータ」を「バイナリデータ」とよびます。バイナリデータのクループには「画像データ(静止画・動画)」や「音声データ」があります。
関連記事:文字コードとは?~UTF-8はパソコンの世界共通語~
データ分析用語:索引




