Amazon Athena と Redshift Spectrum をParquet形式にファイル変換してレスポンスとコストを改善する
- TAG : AWS | Garbage in Big “X” Out | データレイク | ビッグデータ分析
- POSTED : 2018.04.03 12:17
f t p h l

目次
PythonプログラミングだけでParquet形式にファイル変換
AWS(Amazon Web Services)にはクラウドストレージの Amazon S3 に溜まったデータファイルをSQL命令で参照できるデータレイクサービスとして、Amazon Athena と Amazon Redshift Spectrum という2つのサービスがあります。これらを使うことで簡単にデータ参照できるようになるのですが、参照するデータ量が多くなると処理レスポンスと処理ごとのクラウド利用料金が気になってきます。今回は Athena と Redshift Spectrum の両方に適用でき、レスポンスとコストの問題を同時に解決するParquet形式のファイル変換方法についてご説明します。
なぜ、Amazon Redshift Spectrum が必要か?
弊社では Amazon Redshift をデータ分析の中核として利用しています。RedshiftはPostageSQLとほぼ同様の操作性でありながら、複雑な処理命令に対しても比較的早く処理結果を返してくれるため、データ分析の試行錯誤フェーズでは非常に有効なデータベースです。しかし、いくらクラウドデータベースだからと言っても、リソースである処理能力や記憶容量には限界があり、複数の分析者が各々に大量データを投入して複雑な処理を依頼するようなことがあれば、それに対応するためRedshiftのリソース単位であるノードをどんどん増やすことになります。
このRedshiftのリソース問題を解決するものが Redshift Spectrum です。Redshift Spectrum は Amazon S3 上のデータファイルを参照しているため、無制限に大量データを格納でき、容量当たりの月額クラウド利用料金は非常に安いです。(0.025USD/GB/月)また、Redshift Spectrum の処理実行時には Redshift 本体のリソースは使いませんので、ほかのRedshift利用者とリソースの奪い合いになることはありません。
Redshift Spectrum は非常に便利なのですが、カラム数が多い大量のCSV形式などのテキストデータには不向きです。なぜなら大量データから特定のカラムしか使用しない命令処理の場合でも、テキストデータの場合は行単位で処理するため、処理対象が全カラムになってしまいます。また、 Redshift Spectrum の課金体系が、対象データのデータ容量が処理実行の度にかかるため、処理単価(5USD/TB)が安くても回数が多くなれば、それなりの課金が発生する場合があります。
Parquet形式とは
Parquetは正式名「Apache Parquet」というものでカラムナーストレージ形式との事です。ストレージ形式ですのでデータベースやプログラムなどから呼ぶことも可能との事です。
前章で説明したとおり、CSVや一般的なデータベース(RDB)の場合、行単位でデータが登録されています。そのため、データ登録は速いが、特定の列の検索・抽出には不向きです。
そのため、データを行単位でなく列単位で管理する大量データ処理に特化したカラムナー型というデータ保存形式が生まれました。カラムナー型は列単位で登録されているため、特定のカラムだけを効率的にデータ参照できます。また、カラムナー型にすることにより、データ項目のデータ圧縮が行いやすくなり、実際のデータ量の1/2以下にすることが可能になりました。それによって、データ転送が効率的に行えるようになりました。
Pythonプログラミングによる処理手順
CSV形式からParquet形式にファイル変換する方法は下記の簡単3ステップです。
pandasでファイル読込
まず初めにPythonでのデータ分析でお馴染みのpandasにCSVファイルを読み込ませます。変換対象のファイルサイズが1GB以下なら問題がないのですが、巨大になるとpandasへのファイル読込時にメモリ不足で異常終了する場合があります。
そのため下記のようにpandasの「chunksize」パラメタで読み取る行数を指定した方がメモリ使用量も少なく、処理速度も速いです。また、ある程度のファイルサイズで分割した方が、Athena や Redshift Spectrum で自動的に並列分散処理するため処理速度が改善されます。(128MB以上なら良いらしい)
|
1 2 3 4 5 |
import pandas as pd dfs = pd.read_csv('sample.csv', chunksize=10000000) for df in dfs: # 読取範囲内でのデータ型変換処理 |
pandasでデータ型変換
Athena や Redshift Spectrum の外部参照テーブルとParquetファイルのカラムのデータ型を合わせる必要があります。合わせないと外部参照テーブルの使用時にエラーが発生します。
pandasでは読み込んだファイルのデータ状況で自動的に型判定を行ってくれますが、結構いい加減な部分がるため全カラムに対して明示的にデータ型変換を行ってください。また、空文字はデフォルトでNull扱いとなり、「NaN」という値が入り、これも外部参照テーブルの使用時にエラーとなるため置換が必要です。
|
1 2 |
df['文字カラム'] = df['文字カラム'].fillna('').astype(str) df['数値カラム'] = df['数値カラム'].fillna(0.0).astype(float) |
pyarrowでParquetファイル作成
最後にpandasで整形したデータをParquetファイルに出力するだけです。出力されたデータを参照するためには、Athena または Redshift Spectrumの外部参照テーブルで「STORED AS PARQUET」と指定するだけですので、公式ドキュメント(Athena / Redshift Spectrum)を参照すれば難しいことはないと思います。
|
1 2 3 4 5 |
import pyarrow as pa import pyarrow.parquet as pq table = pa.Table.from_pandas(df) pq.write_table(table, 'sample.pq') |
固定フォーマットでデータサイズが大きくなるならParquet形式でデータを蓄積しよう
「無変換で溜め込んだデータを任意のタイミングで参照する」というデータレイクのコンセプトとして、Parquetファイルはデータ変換作業も必要になり、データフォーマットも固定となってしまうため、運用面での自由度はありません。しかし、コストを重視した場合、Parquetファイルは非常に有効な手段です。弊社で検証した時には30億件のデータでもストレスなくデータ参照でき、CSV形式に比べファイルサイズが1/10程度になりました。(データ参照の料金コストだけ考慮するとBigQueryより安いです)
今回、弊社では大量データを一気にデータ変換したため、それなりの時間が掛かってしまいました。しかし、100MB程度のサイズのデータファイルがS3に蓄積されるシステムの場合、AWS Lambda でファイル格納を検知して、Parquet形式にデータ変換し、S3にParquetファイルを戻すサーバーレスバッチを作れるかもしれません。もし、サーバーレスでParquet形式にデータ変換できれば、低コストで大量データを任意のタイミングでデータ参照できるシステムが構築できるかもしれません。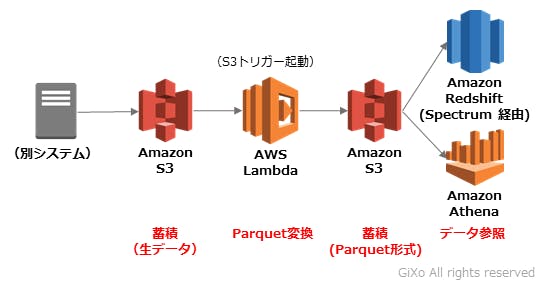

関連記事
f t p h l