第7回(最終回):何が良いかはケースバイケースだ!|CSV、XML、JSON…データフォーマットの変遷について考える
- TAG : Tech & Science | データハンドリング | データフォーマット | マーケティング・テクノロジスト
- POSTED : 2015.02.27 08:51
f t p h l

テキストフォーマット比較・最終回は独断と偏見のまとめです
前回(第6回)は、各フォーマット説明の最後としてJSONフォーマットについて説明しました。今回は本連載の最終回として、これらのまとめを説明します。フォーマット同士の比較や各々のメリットデメリットを述べて生きたいと考えています。まとめなだけに多分に独断と偏見がまざりますがご容赦くださいw。
これまで取り上げてきたこと
本記事でこれまで以下のような内容を取り上げてきました。
- 第1回 いろいろなデータフォーマットが登場しています
- 第2回 データフォーマットを考える上での6つのポイント
- 第3回 フラットフォーマット(固定長フォーマット)について
- 第4回 Character-Separated Valuesフォーマット(CSV,TSV,SSVなど)について
- 第5回 XMLフォーマットについて
- 第6回 JSONフォーマットについて
- 第7回 まとめ(今回)
また、それらの変遷や特徴を考える上で前提として知っておいたほうがよい「データを処理する際の共通的な取り決め」について以下の6つの取り決めを説明しました。
①.データ構造
②.データサイズ(1項目あたり)
③.データサイズ(レコード数)
④.文字コード
⑤.エスケープ文字
⑥.処理速度
各データフォーマットにマルバツをつけてみる
これまでの本連載6回の記事で取り上げてきたことを元に、私の独断でこれら4フォーマットと6つの取り決めについてマルバツ表をあらわしてみました。
まず、総合的なマルバツ表です。
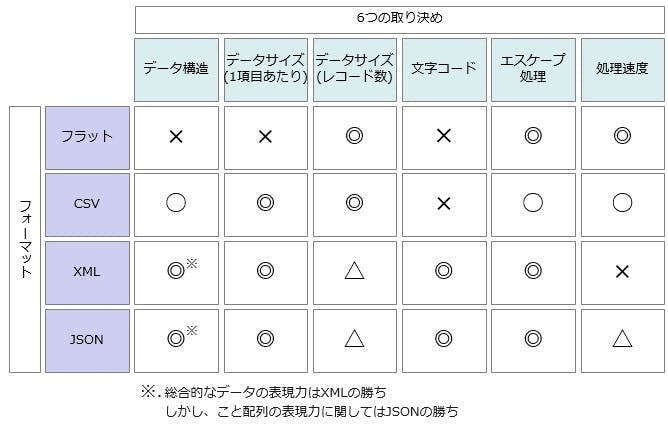
やはり、新しいフォーマットであるXMLやJSONに多くのマルがありますね。データフォーマットの変遷に伴ってデータを処理する上での取り決めがどんどんデータフォーマット側で取り決められるようになった事によって、
「データの自由度や再利用性が向上し、データの扱いが便利になっている」
という事がおわかりいただけると思います。
しかし「便利とは何か?」は利用シーンによって違う
例えば、「インターネットで1件の買い物をするときの処理」と「ある会社が1ヶ月に一回、全ての売り上げを分析データベースに投入する処理」では「データの利用シーン」が異なります。以前の連載(第2回)で私は「データフォーマットの違い」とは「上記6つの取り決めそれぞれに関して、それぞれをトレードオフしながら効率的に処理を行っていくための答えある」と書きました。利用シーンが異なれば一番便利なデータフォーマットも異なるということです。以下にその違いを述べてみましょう。
●インターネットで1件の買い物をするときの処理(トランザクション処理)
このような処理の場合、上記の取り決めのうちデータサイズ(レコード数)は小さいのでトレードオフの中で妥協してもかまわない処理になります。また処理速度に関しても一回のデータ量が少ないので妥協をしてもフォーマットの違いにおける処理速度の違いは結果的に誤差の範囲に収まります。大切なのは頻繁に発生する仕様変更への対応速度や変更による障害の軽減、そしてそのデータが様々なシステム(プロセス)を最も効率的に渡り歩く為の再利用性の高さです。これらを鑑みた上で、上記のマルバツ表から妥協できる項目を除外してみました。どうなるでしょうか?
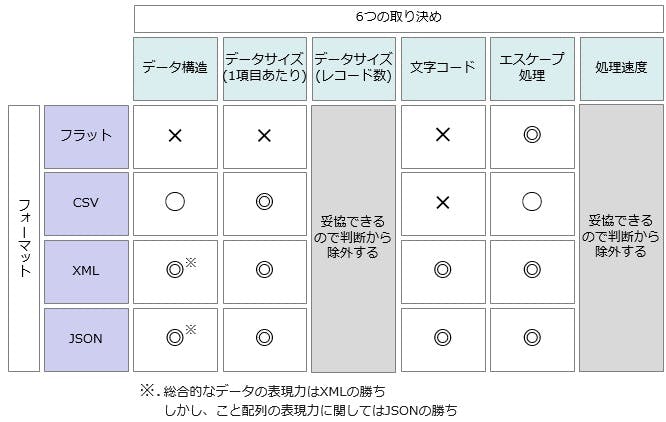
XMLやJSONの強さが際立ったと思います。ほぼ満点ですね笑。この様な処理をOLTP(Online Transaction Processing)と呼びます。「データ量はそこそこだがやりとりが頻繁に発生する、ついでに仕様変更も頻繁に発生する(泣)」処理です。言い換えれば、ネットの重要性が増すにつれOLTPが社会の基盤として高まってきた中でXMLやJSONが広く受け入れられてきた、もしくはそういった社会の求めに応じてこれらのフォーマットが生まれた、とも言えるのではないでしょうか。
●ある会社が1ヶ月に一回、全ての売り上げを分析データベースに投入する処理(ビッグデータ処理)
このような処理の場合、データの構造に関する取り決めはトレードオフとして妥協してもかまわない傾向があります。「文字コードやエスケープに関する仕様はこのシステムの中でプログラムとしてガッチリ決めてしまうから、データ側に優れた取り決めを求めない」「仕様の変更もあまり発生しない」と考えられるからです。そのかわり「大量のデータが一度に流れ込むからレコード数や処理速度は妥協できない」という特性がフォーマットに必要とされるわけです。これらを鑑みた上で、上記のマルバツ表から妥協できる項目を除外してみました。どうなるでしょうか?
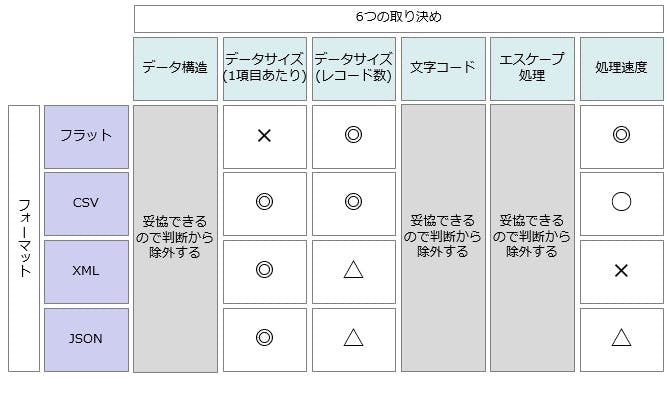
「おお!なんかCSVがいい感じ!」というふうに見えませんか?少なくともXMLが向かないのはお分かりいただけると思います。フラットフォーマットも◎が2個なのですが、いかんせん1項目あたりのデータサイズに×がついているのは痛いですね。実はまさにここにおいて「CSVのいい感じ」が発揮されるのです。その一例として顕著なのが、Amazonクラウドのビックデータ向けデータベースサービスである「Amazon Redshift」の標準的なデータ投入フォーマットはCSVを採用しているのです。最近JSONフォーマットも採用されたのですがそのJSONフォーマットは純粋なJSONフォーマットではなく「CSVのようなJSONフォーマット」なのです(☆)。「これぞまさにトレードオフ!」という感じですね。
(上記の☆についての補足です。Redshiftの「CSVのようなJSONフォーマット」とは、「1ファイルの中の1レコード1レコードが1つのJSONフォーマットになっている」「全体として1つの木構造を形成することをやめた」というフォーマットになっています。この点においてはフラットフォーマットやCSVフォーマットの考え方を導入しています。実はこれも非常に興味深い点で、私はAmazonさんの「JSONの木構造はビックデータには苦しいんだよ!でもJSONって便利なんだよ!!使ったほうがいいんだよ!!」という「いい感じの折衷感」を感じるのです。JSONの広がりとその理由を実感した気がしました。)
ここまで読んでいただいて「お?XMLについてはあまり触れてなくない?地味じゃない?」とお感じになる方もいらっしゃると思うのでXMLを褒めます。XMLの「データに関する取り決めを可能な限りデータ側に格納する」という思想は革新的で現在我々はその恩恵を十二分に受けています。私は常に「ああ、XMLさんありがとう」と思いながらシステムと関わっています。それが「その先のもっと便利なものを」という気持ちの芽生えとなりJSONを生んだ一因になったのです。(XMLさん、こんな持ち上げ方でいいですよね?)
本連載の終わりに
これまでデータフォーマットの変遷やその特徴を7回にわたって説明させていただきました。こうして見ていくとITの技術要素に過ぎないデータフォーマット一つとっても社会の変遷や求めと決して無関係ではないと思います。言い換えれば今あるデータフォーマットにもっとより良いものを求めたいという要求や希望がこれからの社会に求められる物の合わせ鏡になるのかもしれません。私自身も本連載を通じて「じゃあこれから何が必要なのかな?」という未来を考えてみようと思います(まだ考えてませんよ笑)。
以上全7回、ありがとうございました。来週から新しい連載がスタートします。よろしくおねがいいたします。
本連載について
- 第1回 いろいろなデータフォーマットが登場しています
- 第2回 データフォーマットを考える上での6つのポイント
- 第3回 フラットフォーマット(固定長フォーマット)について
- 第4回 Character-Separated Valuesフォーマット(CSV,TSV,SSVなど)について
- 第5回 XMLフォーマットについて
- 第6回 JSONフォーマットについて
- 第7回 まとめ
f t p h l