第2回:CRISP-DMとギックス分析プロセスの違い (1/2)|ギックスのビッグデータ分析体系2.0
- TAG : GiXo コンポーネント | Tech & Science | ビッグデータ分析
- POSTED : 2014.11.25 09:00
f t p h l

目次
データマイニングだけでなく、仮説検証にも活用したい
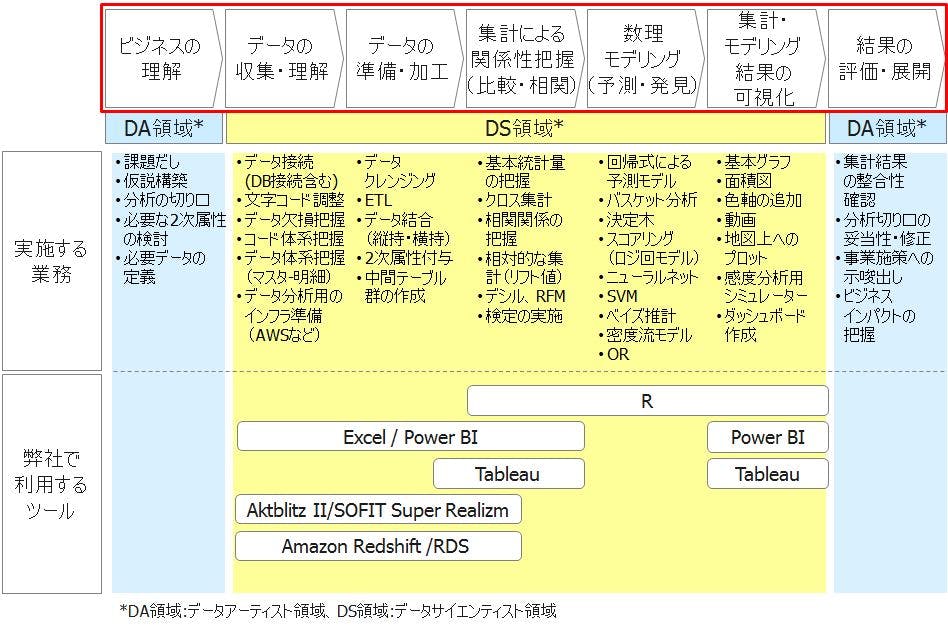
前回の記事で紹介したように、2014年10月にギックスの分析体系を更新しました。その更新に伴い、弊社の分析業務を棚卸しすると同時に、様々な文献をあたり、また専門家と議論しながら改めて分析業務の統計的な意味合いや言葉の定義を再考しました。この連載では、分析体系の更新過程で考慮したことの中で、皆様にお伝えし役立てていただきたい内容をピックアップして紹介していきます。今回、次回と2回に渡って、ギックスの分析体系の中で横軸に取られている分析プロセスについて、データマイニングの標準プロセスであるCRISP-DMと比較しながら考察します。(ビッグデータ分析体系2.0の図では以下の赤枠の線にあたる部分です)
CRISP-DMとの相違点① 集計による関係性の把握
ギックスの分析体系の分析プロセスは、1年前に書いたこちらの記事でも紹介した通り、CRISP-DMを参照して作成しています。CRISP-DM(Cross-Industry Standard Process for Data Mining)は、データマイニングのための標準プロセスとしてSPSS(現在IBMが買収)、NCR、ダイムラークライスラー、OHRAなどがメンバーになったコンソーシアムで開発されました。CSRISP-DMは、汎用性の高いよくできたプロセスですが、我々の業務上の分析プロセスとして活用するにあたっていくつかの改良を加えています。まず本日紹介する一つ目の改良点は、下図のように『集計による関係性把握(比較・相関)』というプロセスを加えている点です。
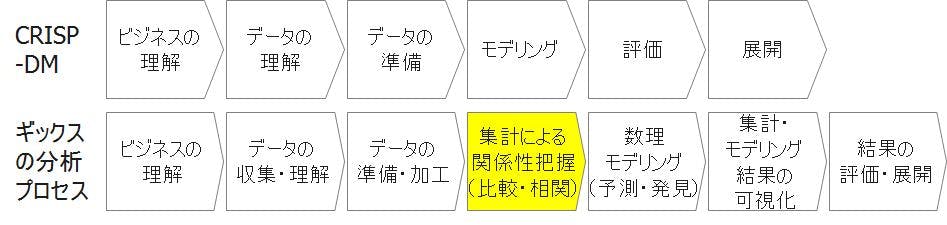
ギックスが通常行う分析では、何かしらの「ビジネス視点での仮説」を分析する前に持っており、その検証のためにデータを集計したり相関関係を把握します。これが「集計による関係性把握(比較・相関)」と定義しているプロセスで、ギックスの分析体系の中では肝ともいえる重要なものです。この部分を実施することで、言い換えると、次のプロセスの数理モデリングを実施しなくても仮説の検証結果が出せるケースも多々ありません。
このように我々にとっては重要なプロセスである集計ですが、CRISP-DMには存在しません。別の言い方をすると、あえてそのプロセスが括りだされていません。なぜCRISP-DMでは、「集計による関係性の把握」がなくいきなり「モデリング」というプロセスになるのでしょうか。
CRISP-DMはデータマイニングのための標準プロセス
それはCRISP-DMが「データマイニング用」の標準プロセスであるからです。この「データマイニング用」というところがポイントです。
データマイニングとは、「明示されておらず今まで知られていなかったが、役立つ可能性があり、かつ、自明でない情報をデータから抽出すること」、「データの巨大集合やデータベースから有用な情報を抽出する技術体系」などと定義されます(Wikipedia)。つまり、データマイニングは、データの中にに何が眠っているかはわからないが、何かしらのアルゴリズムでデータを掘り起し、これまで気づいていなかったことを”発見する”ということを目的にします。人が頭で演繹的にイシューについて考えるのではなく、データからマイニングアルゴリズムを介して帰納的に新しい気づきを発掘するアプローチとも言えます。
このような立ち位置のデータマイニングでは、データの構造を把握したり仮説を検証するための集計は重要でなく、データを上手に掘り起こす優れたモデルを構築するということが重視されます。そういった背景があるため、CRISP-DMでは「集計による関係性の把握」というプロセスがなく、いきなり「モデリング」というプロセスになっていると推測されます。
データマイニングが分析実務でどこまで使えるのか
では、実際のビジネス課題に対して答えを出すためのデータ分析で、データマイニングはどこまで使えるのでしょうか。もちろんデータマイニングは非常に強力な手法で、弊社の分析業務でもマーケティングバスケット分析や決定木などのデータマイニング的な手法は頻繁に活用します。ただ注意しなければいけないのは、データマイニングは出たとこ勝負的な一面があるということです。実際にモデルを回してみないとデータに面白い気づきが眠っているのか、ビジネス上の課題に本当に答えている発見なのかはわかりません。
一方で、上述した通り、わざわざ数理的なモデルを作らなくても、よりシンプルな集計や相関関係の把握でビジネス上の仮説を検証することで、分析の目的に達するケースが非常に多いです。特にビジネス上の仮説がしっかりと立案できている場合は、仮説検証のための『集計』に注力して仮説検証を繰り返したほうが経験上効率がいいです。分析の種類にもよりますが、ギックスの場合のこれまでの分析業務において、数理的なモデルを作る必要があったケースは全体の分析数のは1-2割程度にとどまります。
ギックス分析プロセスは仮説検証型分析にもデータマイニング型分析にも適用できる
上記のような経験則からも、ギックスでは、まず仮説検証のための集計作業を実直に繰り返すということを重視します。データマイニングの手法も利用しますが、集計作業をしっかりとしたうえでより面白い発見ができるかもしれないというオプション的な位置づけにとどまります。もちろん読者の皆様には、分析の目的に応じて「集計」と「モデリング」への注力配分は変えていっていただければと思います。ただ、ビジネス課題を解決するという分析業務においてはモデリングだけではなく、仮説検証のための集計にもぜひ注力していただきたいという思いを込めて、ギックスの分析プロセスには「集計による関係性」というプロセスを加えているということをお伝えしたかった次第です。
次回も今回に引き続いて、ギックスの分析について話を進めたいと思います。次回は、分析プロセス後半の集計・モデリング結果の可視化についての紹介です。
f t p h l