pandas でヘッダーが複数ある POS データを縦持ち横持ち変換する(前編)
- TAG : Advent Calendar | excel | multiindex | pandas | pivot | python | Tech & Science | unpivot | 横持ち | 縦持ち
- POSTED : 2020.12.11 08:21
f t p h l

この記事は GiXo アドベントカレンダー の11日目の記事です。
昨日は、非エンジニアの Kaggler がエンジニア指南を受けて気づいた、たった1つのことでした。
Technology div. の緒方です。
本記事では、 pandas で複数行のヘッダーを持つテーブルを縦持ち横持ち変換する方法についてご紹介します。特に調べても加工の方法が見つからなかった処理として、ヘッダー行が複数ある場合の縦持ち変換する方法に焦点を当てて紹介していきます。
また次回の記事ではより一般化してコードを使いまわせるように書き換えてみます。
昨今では多くの企業でデータを扱うことが当たり前になりました。しかし元データに前処理が必要なケースが多々あり、前処理だけで膨大な工数がかかることも珍しくありません。この記事を読まれた方が、ヘッダーが複数行あるケースにはまることなく処理を書いて少しでも工数を減らしていただければ幸いです。
なお、pandas の基本についてはすでに世の中に良質な記事や本が大量に出回っているため紹介しません。
今回扱うデータについて
今回は次のように店舗名と指標が横持ちにされているデータを例にします。


データの加工に慣れていない人はこのようなデータを見て驚いてしまうかもしれません。そもそもなぜ Excel 形式なのかとか、店舗を横持ちにするメリットはなんなのかと突っ込みたくなるかもしれません。しかし実務で様々なデータを見てきた経験上、このデータは POS においては比較的よくあるパターンの1つです。加工自体はそれほど難しくありませんが、私自身はまるポイントがあったので今回の記事を執筆しています。
今回の記事の目標はこのデータを次の画像のようないわゆる素直なテーブルに変換することです。

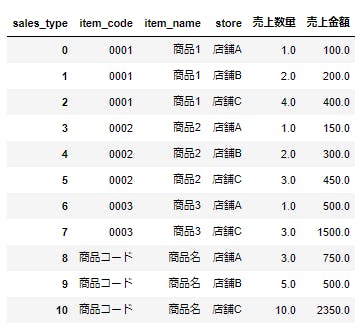
加工手順
今回のデータの加工手順は大きく次の2つに分けることができます。
- 複数行(1行目と2行目)を縦持ちに変換する
- 売上金額と売上数量を横持ちに変換する
複数行を縦持ちに変換する
私がはまったポイントがこの「複数行を縦持ちに変換する」というところです。調べても分からず色々と実装して最終的に縦持ち変換部分のコードは次のようになりました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
import pandas as pd # ファイルの読み込み df = pd.read_excel( 'サンプルデータ.xlsx', header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:2]) value_vars = list(df.columns[4:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) |
DataFrame.melt を用いて縦持ち変換するためには id_vars と value_vars を指定する必要があります。どちらもヘッダー名を指定するのですが、複数行ある場合のうまいやり方が分からずはまりました。
結局のところ、ファイルの読み込みの時点で複数行を読み込んでおけば df.columns でヘッダー名を取り出すことができるため、 id_vars と value_vars を指定することができることに気づきました。ただし複数行を読み込んだ場合のヘッダーは MultiIndex になるため、 list() を用いてリストに変更しておく必要があります。変更しない場合は次のようなエラーが発生します 。
|
1 |
ValueError: id_vars must be a list of tuples when columns are a MultiIndex |
縦持ちへの変換が終わった時点で次のようなデータになっているはずです。


続いてこのテーブルを横持ちに変換していきます。
横持ちに変換する
横持ちに変換するところは特筆するところはありません。このままではカラム名がマルチインデックスとなっていて扱いにくいので変更したうえで横持ちに変換します。
|
1 2 3 4 5 6 7 8 9 |
# カラム名を変更する df.columns = ['item_code', 'item_name', 'store', 'sales_type', 'value'] # 横持ちに変換する df = df.pivot_table( index=['item_code', 'item_name', 'store'], columns=['sales_type'], values='value', ) |
ここまで実行することで次のようなテーブルができます。


この状態ではカラムは売上数量と売上金額です。横持ちにする際に index として指定したものはマルチインデックスになっています。このままでは扱いにくいので reset_index を使用してインデックスをカラムに戻します。
|
1 2 |
df.reset_index(inplace=True) df |

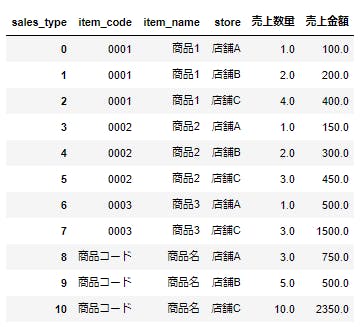
複数行のヘッダーがある場合はところどころにマルチインデックスが現れるため、マルチインデックスの扱いに注意が必要です。
ここまでのコードをまとめると次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import pandas as pd # ファイルの読み込み df = pd.read_excel( 'サンプルデータ.xlsx', header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:2]) value_vars = list(df.columns[4:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) # カラム名を変更する df.columns = ['item_code', 'item_name', 'store', 'sales_type', 'value'] # 横持ち変換する df = df.pivot_table( index=['item_code', 'item_name', 'store'], columns=['sales_type'], values='value', ) df.reset_index(inplace=True) |
次回予告
さて、ここまでで複数行のヘッダーがある場合のデータを縦持ち横持ち変換して素直な形のテーブルに変更することができました。
冒頭でも述べましたが、今回扱ったデータは POS データとしては比較的よく見かけるデータです。2, 3回似たようなコードを書くのならまだしも、これをヘッダー行やカラム名を微妙に変更して何回も書くのは苦痛ですし工数もかさみます。
そこで次回はより汎用的に処理できるようにコードを書き換えてみたいと思います。明日は「pandas でヘッダーが複数ある POS データを縦持ち横持ち変換する(後編)」を公開予定です。
Satoshi Ogata
Technology Div. 所属
データ分析基盤やデータの前処理について情報発信します。
f t p h l