構造化データと非構造化データとデータの規則性|データ分析用語を解説
f t p h l

本記事は、株式会社ギックスの運営していた分析情報サイト graffe/グラーフ より移設されました(2019/7/1)
目次
非構造化データには規則性が”ある”データと”ない”データの2種類がある
近年、ビックデータ分析として、非構造化データの分析が注目されています。しかし、非構造化データの種類によっては、データ分析に向き、不向きがあります。今回は、構造化データと非構造化データの関係性に触れながら、非構造化データの規則性が”ある”データと”ない”データについて説明したいと思います。
構造化データと非構造化データの関係
下記の図が、構造化データと非構造化データと「規則性があるデータ」の関係図です。そして、「規則性があるデータ」については、境界線が非常に曖昧です。これから、各データについて説明します。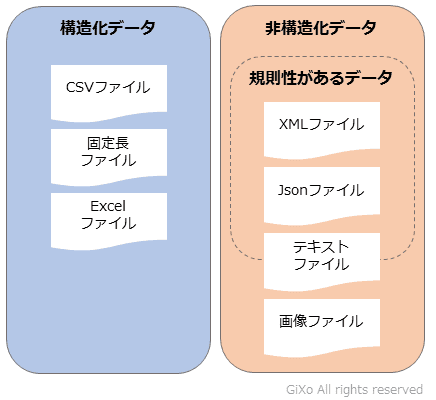
構造化データ
従来より、商業活動や自然現象などを数値化した意味のあるデータ(情報)として活用してきた。そのような数値データを、より効率的に、より生産的に活用するために、計算機(コンピュータ)が生まれ、活用が高度化していく中で、主にリレーショナルモデルをベースとしたデータベースに構造化して格納されて活用したため、そのようなデータをのちに構造化データと呼ぶようになった。
Wikipedia:「非構造化データ」より抜粋
Wikipediaによると、先にリレーショナルデータベース(略称:RDB)ができ、そのRDBのテーブルに合うデータの事を構造化データという事になり、先に”物”が出来てから”言葉”ができた珍しい起源の言葉のようです。
一般的に構造化データと言ったとき、CSVファイルやExcelファイルの表のように、”列”と”行”の概念のあるデータを指します。この”列”の個数と順番が、常に一定であることから、別名「定型データ」とも呼ばれています。
データ分析では、構造化データが最も分析に適しています。なぜなら、「どこに何があるか」が列によって決まっているため、集計、比較などが行いやすいです。そのため、データ分析で最も使用されているデータ構造です。
非構造化データ
規則性がある非構造化データ
先ほどの説明でも説明しましたが、データ分析で構造化データが、データ分析で使われてきましが、近年、ビッグデータ分析が、各企業で行われるようになり、非構造化データのデータ分析も頻繁に行われるようになってきています。しかし、全ての非構造化データがデータ分析に向いているわけではありません。この中でXMLファイルやJsonファイルなどの「規則性があるデータ」が、データ分析の対象になってきます。
「規則性がある非構造化データ」とは何か? 構造化データの場合、「列」という概念があり、登録できる情報に制限がありました。しかし、「規則性がある非構造化データ」には、列の概念がありません。その代わりに、XMLファイルなどには、ルール(規則性)があり、情報を登録・取得する方法が決まっています。そのため、情報量が決まらない、または拡張する可能性があるデータには、「規則性がある非構造化データ」が使われることが多くなり、インターネットの通信情報などで頻繁に使用されています。
規則性がない非構造化データ
XMLファイルやJsonファイルなどは、ルール(規則性)があるため、データの取得は100%の精度で行うことができました。しかし、メール文やワード文章などは、ルールが無いため、データの取得は100%の精度で行うことはできません。そのため、分析でできることは、文章中の文字列を探す「キーワード検索」ぐらいです。
「規則性がない非構造化データ」から規則性を見つける技術は進化している
このようにデータ分析で活用できるデータ種類は、「構造化データ」と「規則性がある非構造化データ」に限定されています。しかし、近年、言語解析などを使用して、文章を分解して、データとして抽出する技術も出てきています。これらの技術を使用して、今まで「規則性がなかったデータ」から規則性を見つけることで、データとして活用が可能になってきています。今後、ビッグデータの技術進化とともに、これらの分析方法が進化し、今まで扱えなかったデータを分析できるようになって行くと思います。
関連記事
f t p h l