データレイクとクラウドサービス ~①データレイクの今までをおさらい~
- TAG : Tech & Science | データハンドリング | データレイク | ビッグデータ分析 | ビッグデータ活用
- POSTED : 2017.06.05 07:58
f t p h l

目次
データレイクはビッグデータ分析とともに常に進化している
ちょうど2年前。弊社ブログで「データレイク(Data Lake)」について取り上げさせていただきました。その当時「データレイク」という言葉だけが先行し、何を使えばよいか、どんな場面で使えるかがボヤっとしていました。しかし、2年も経つとデータレイクのテクノロジが多く発表され、手を伸ばせば届くところまで来ています。今回から2回に渡って、データレイクのおさらいと、それらを実現するテクノロジ、そしてこれからの課題についてご説明したいと思います。
データレイク(Data Lake)とは?
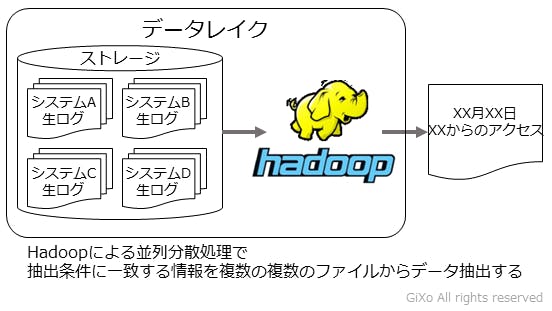
「データレイク」とはデータを扱うための概念でしかありません。Data Lake(データの湖)の名前が示すように、多くの支流(ルート)からデータファイルをかき集めため、貯めこんでいる巨大なデータファイルの集積場所です。
データファイルの集積場所というとファイルサーバーをイメージすると思いますが、データレイクはただデータファイルを貯めるためではなく、データファイルをデータとして効率的に参照できるストレージシステムの事を指しています。(データレイクとして使用できるストレージ単体でもデータレイクという事もあるようです)
このようにデータレイクは「概念」であるため、「これが正解」という具体的な定義・手法がある物ではありません。そのため、世の中のデータレイクの製品/サービスも微妙に異なっていますが、だいたい以下の共通点があると思っています。
- ログファイルや画像ファイル、音声ファイルなどを未加工のままストレージ(記憶ディスク)に貯めこむ
- 必要な時に貯めこんだデータファイルの内容を横断的に検索・参照できる
- 検索・参照にはHadoopなどの分散処理基盤を使用する
- 検索・参照にはSQL命令に類似する命令文で行う事が主流

データベースと何が違うの?
データレイクは一般的なリレーショナルデータベース(以下、RDB)と似て非なる物です。データレイク技術はビッグデータ分析でのRDB特有の悩みから生まれたといっても過言ではありません。
RDBのテーブルはExcelのような行(レコード)と列(カラム)の形で登録・管理されています。この形式は構造化データと呼ばれ、「どこに何があるか」が列によって決まっているため、データ管理しやすく、集計や比較などが行いやすいことから十数年もの長い間、データ管理の中核機能として利用されてきました。
しかし、ビッグデータ分析技術が進化するにつれて、非構造化データにスポットライトが当たり始め、既存のRDBでは対応できなくなってきました。なぜなら、RDBのデータ管理はテーブル構造に依存してしまい、列の数や順番が定まらない非構造データは取り扱う事が出来ないためです。更に大量のデータを扱うことになり、今まで想像すらできなかったボリュームの記憶容量が必要となってきました。
そのため、RDBに変わる新しいデータ参照機能としてデータレイク技術が進歩してきました。データレイクはRDBのテーブルのような決まった形に整形する必要はなく、データファイルそのままをストレージに保存します。その後、データ参照するための定義を行うことで非構造化データに対してデータ参照することができます。また、データベース内にデータを保存する必要がないため、データベースの記憶容量を気にすることはありません。
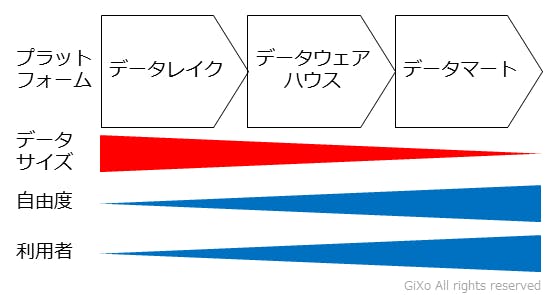
「データレイク > データウェアハウス > データマート」の関係
データレイクはRDBより扱えるデータ形式もデータサイズも多いのが特徴です。そのためRDBが担っているデータウェアハウスはデータレイクに移行すると思われるかもしれませんが、そんなことは絶対にありません。ここで、データレイクとデータウェアハウス、そしてデータマートの役割について整理したいと思います。
データレイクは環境さえ整えばペタバイト(テラバイトの1,000倍)クラスのデータ参照も可能です。しかし、データレイクはデータ参照のみでデータの追加・更新・削除は行えません。データの追加・更新・削除はデータレイクのストレージ上のデータファイルを追加・更新・削除する必要があります。更にデータレイクは「どんなデータファイルでも貯められる」ため、データとして不適切な情報がファイル内に含まれていても保存されてしまいます。そのため、データレイクはデータを正しい形で登録・管理する機能としては不十分です。
反面、RDBのデータウェアハウスは、データベースの機能によって厳格にデータ登録・管理が可能です。しかし、管理できるストレージサイズには限界があります。そのため、データレイクから必要な情報のみを抽出・集約し、RDBのデータウェアハウスに入るデータ形式とデータサイズで登録する必要があります。
そして、データマートは最終的なデータ利用者のために利用します。データウェアハウス用のRDBは大量データを分析には特化していますが、1度に多くのリクエストに対して同時に処理できる事には不向きです。例えば多くの利用者が一斉にBIツールなどでデータ参照をしてしまうと処理待ちが発生していまいます。そのため、データウェアハウスとは別のRDBを用意し、それぞれの利用者にあわせたデータウェアハウスデータの集出・集約結果を登録する必要があります。
この様にデータレイク、データウェアハウス、データマートは、求められるデータサイズや要件が違うため、それぞれ別々のプラットフォームを用意し、データ形式やサイズに合わせながら登録していくことが必要です。

データレイクとクラウドサービスは切っても切れない関係
データレイク技術が急激に進歩してきた背景にはクラウドサービスの進歩があります。
データレイクに必要な機器を揃えようとすると大掛かりなアクションを起こす必要なありました。ペタバイトクラスの大量データを保存するストレージ、そして、Hadoopなどの分散処理基盤を実行させるための大量のサーバーなどが必要になります。これらを用意するためには大量の資金、物理スペース、セットアップ時間と専門技術が必要でした。
しかし、クラウドサービスのクラウドストレージを利用すれば、1ギガバイト当たり月々数円から容量無制限にデータ保存可能です。そして、Hadoop機能をパッケージングした分散処理クラウドサービスがあります。これらを使うことでコストと技術のハードルが低くなり、クイックにデータレイクを導入できるようになりました。
次回は各社のクラウドサービスを例に出し、クラウドサービスによってデータレイクはどの様に進化したかをご説明したいと思います。
関連記事
- データレイクとクラウドサービス ~①データレイクの今までをおさらい~ (本稿)
- データレイクとクラウドサービス ~②クラウドサービスが支えるこれからのデータレイク~
- データレイクとクラウドサービス ~③クラウドストレージの賢い管理方法~
f t p h l